
SCI Publications
2012
![]()
A. Humphrey, Q. Meng, M. Berzins, T. Harman.
“Radiation Modeling Using the Uintah Heterogeneous CPU/GPU Runtime System,” SCI Technical Report, No. UUSCI-2012-003, SCI Institute, University of Utah, 2012.
The Uintah Computational Framework was developed to provide an environment for solving fluid-structure interaction problems on structured adaptive grids on large-scale, long-running, data-intensive problems. Uintah uses a combination of fluid-flow solvers and particle-based methods for solids, together with a novel asynchronous task-based approach with fully automated load balancing. Uintah demonstrates excellent weak and strong scalability at full machine capacity on XSEDE resources such as Ranger and Kraken, and through the use of a hybrid memory approach based on a combination of MPI and Pthreads, Uintah now runs on up to 262k cores on the DOE Jaguar system. In order to extend Uintah to heterogeneous systems, with ever-increasing CPU core counts and additional onnode GPUs, a new dynamic CPU-GPU task scheduler is designed and evaluated in this study. This new scheduler enables Uintah to fully exploit these architectures with support for asynchronous, outof- order scheduling of both CPU and GPU computational tasks. A new runtime system has also been implemented with an added multi-stage queuing architecture for efficient scheduling of CPU and GPU tasks. This new runtime system automatically handles the details of asynchronous memory copies to and from the GPU and introduces a novel method of pre-fetching and preparing GPU memory prior to GPU task execution. In this study this new design is examined in the context of a developing, hierarchical GPUbased ray tracing radiation transport model that provides Uintah with additional capabilities for heat transfer and electromagnetic wave propagation. The capabilities of this new scheduler design are tested by running at large scale on the modern heterogeneous systems, Keeneland and TitanDev, with up to 360 and 960 GPUs respectively. On these systems, we demonstrate significant speedups per GPU against a standard CPU core for our radiation problem.
Keywords: csafe, uintah
![]()
A. Humphrey, Q. Meng, M. Berzins, T. Harman.
“Radiation Modeling Using the Uintah Heterogeneous CPU/GPU Runtime System,” In Proceedings of the first conference of the Extreme Science and Engineering Discovery Environment (XSEDE'12), Association for Computing Machinery, 2012.
DOI: 10.1145/2335755.2335791
The Uintah Computational Framework was developed to provide an environment for solving fluid-structure interaction problems on structured adaptive grids on large-scale, long-running, data-intensive problems. Uintah uses a combination of fluid-flow solvers and particle-based methods for solids, together with a novel asynchronous task-based approach with fully automated load balancing. Uintah demonstrates excellent weak and strong scalability at full machine capacity on XSEDE resources such as Ranger and Kraken, and through the use of a hybrid memory approach based on a combination of MPI and Pthreads, Uintah now runs on up to 262k cores on the DOE Jaguar system. In order to extend Uintah to heterogeneous systems, with ever-increasing CPU core counts and additional onnode GPUs, a new dynamic CPU-GPU task scheduler is designed and evaluated in this study. This new scheduler enables Uintah to fully exploit these architectures with support for asynchronous, outof- order scheduling of both CPU and GPU computational tasks. A new runtime system has also been implemented with an added multi-stage queuing architecture for efficient scheduling of CPU and GPU tasks. This new runtime system automatically handles the details of asynchronous memory copies to and from the GPU and introduces a novel method of pre-fetching and preparing GPU memory prior to GPU task execution. In this study this new design is examined in the context of a developing, hierarchical GPUbased ray tracing radiation transport model that provides Uintah with additional capabilities for heat transfer and electromagnetic wave propagation. The capabilities of this new scheduler design are tested by running at large scale on the modern heterogeneous systems, Keeneland and TitanDev, with up to 360 and 960 GPUs respectively. On these systems, we demonstrate significant speedups per GPU against a standard CPU core for our radiation problem.
Keywords: Uintah, hybrid parallelism, scalability, parallel, adaptive, GPU, heterogeneous systems, Keeneland, TitanDev
![]()
H. Lu, M. Berzins, C.E. Goodyer, P.K. Jimack.
“Adaptive High-Order Discontinuous Galerkin Solution of Elastohydrodynamic Lubrication Point Contact Problems,” In Advances in Engineering Software, Vol. 45, No. 1, pp. 313--324. 2012.
DOI: 10.1016/j.advengsoft.2011.10.006
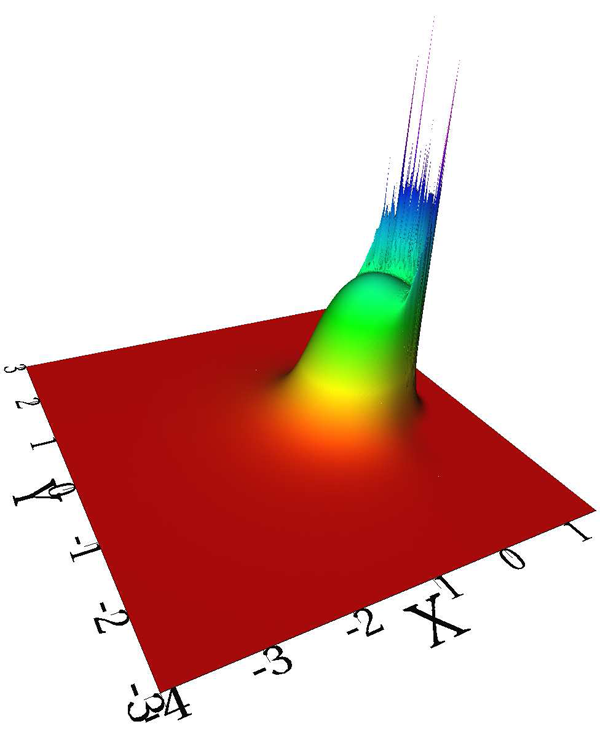
Keywords: Elastohydrodynamic lubrication, Discontinuous Galerkin, High polynomial degree, h-adaptivity, Nonlinear systems
![]()
Q. Meng, M. Berzins.
“Scalable Large-scale Fluid-structure Interaction Solvers in the Uintah Framework via Hybrid Task-based Parallelism Algorithms,” SCI Technical Report, No. UUSCI-2012-004, SCI Institute, University of Utah, 2012.
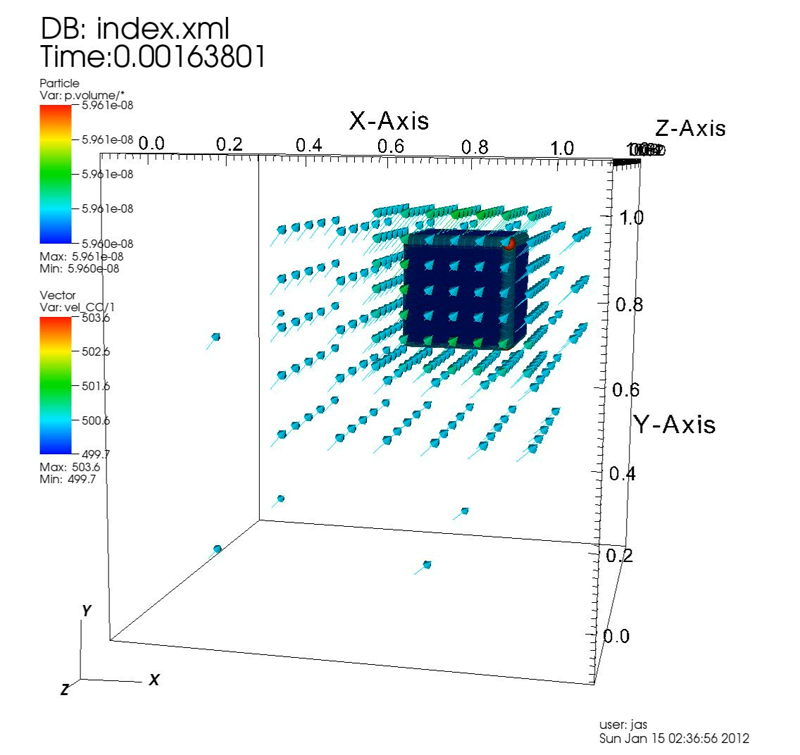
Keywords: uintah, csafe
![]()
Q. Meng, A. Humphrey, M. Berzins.
“The Uintah Framework: A Unified Heterogeneous Task Scheduling and Runtime System,” In Digital Proceedings of The International Conference for High Performance Computing, Networking, Storage and Analysis, Note: SC’12 –2nd International Workshop on Domain-Specific Languages and High-Level Frameworks for High Performance Computing, WOLFHPC 2012, pp. 2441--2448. 2012.
DOI: 10.1109/SCC.2012.6674233
The development of a new unified, multi-threaded runtime system for the execution of asynchronous tasks on heterogeneous systems is described in this work. These asynchronous tasks arise from the Uintah framework, which was developed to provide an environment for solving a broad class of fluid-structure interaction problems on structured adaptive grids. Uintah has a clear separation between its MPI-free user-coded tasks and its runtime system that ensures these tasks execute efficiently. This separation also allows for complete isolation of the application developer from the complexities involved with the parallelism Uintah provides. While we have designed scalable runtime systems for large CPU core counts, the emergence of heterogeneous systems, with additional on-node accelerators and co-processors presents additional design challenges in terms of effectively utilizing all computational resources on-node and managing multiple levels of parallelism. Our work addresses these challenges for Uintah by the development of new hybrid runtime system and Unified multi-threaded MPI task scheduler, enabling Uintah to fully exploit current and emerging architectures with support for asynchronous, out-of-order scheduling of both CPU and GPU computational tasks. This design coupled with an approach that uses MPI to communicate between nodes, a shared memory model on-node and the use of novel lock-free data structures, has made it possible for Uintah to achieve excellent scalability for challenging fluid-structure problems using adaptive mesh refinement on as many as 256K cores on the DoE Jaguar XK6 system. This design has also demonstrated an ability to run capability jobs on the heterogeneous systems, Keeneland and TitanDev. In this work, the evolution of Uintah and its runtime system is examined in the context of our new Unified multi-threaded scheduler design. The performance of the Unified scheduler is also tested against previous Uintah scheduler and runtime designs over a range of processor core and GPU counts.
![]()
J.R. Peterson, J.C. Beckvermit, T. Harman, M. Berzins, C.A. Wight.
“Multiscale Modeling of High Explosives for Transportation Accidents,” In Proceedings of the 1st Conference of the Extreme Science and Engineering Discovery Environment: Bridging from the eXtreme to the campus and beyond, 2012.
DOI: 10.1145/2335755.2335828
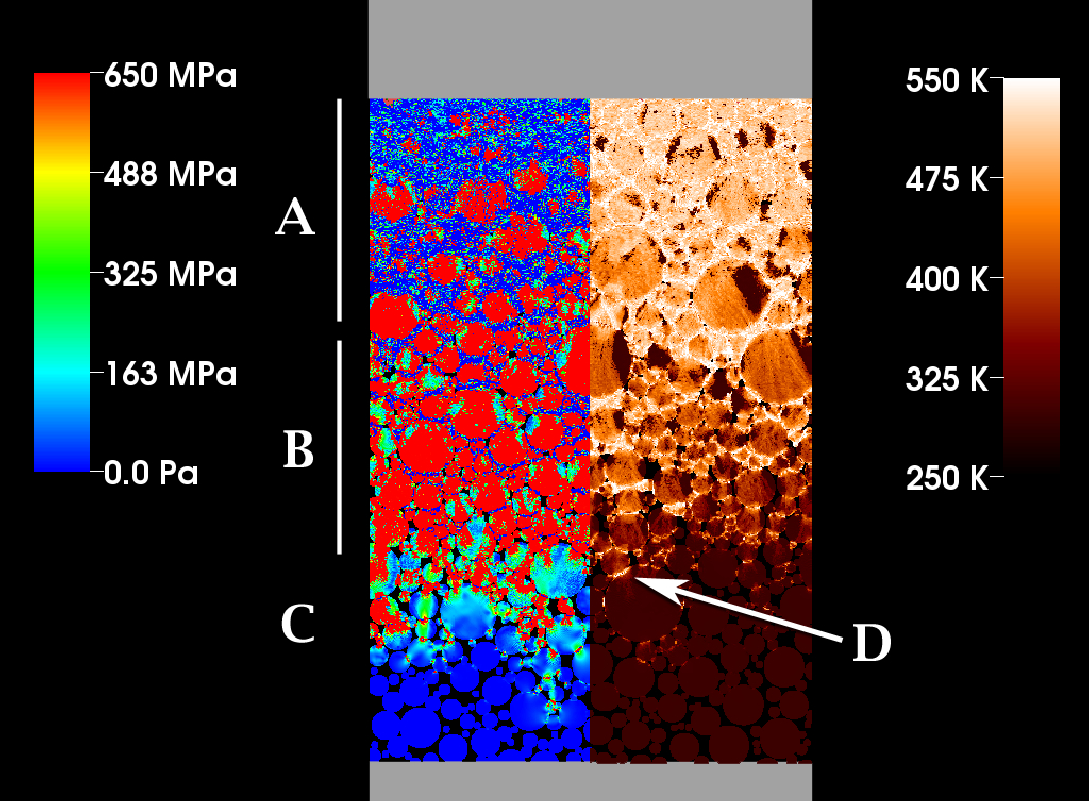
![]()
J. Schmidt, M. Berzins, J. Thornock, T. Saad, J. Sutherland.
“Large Scale Parallel Solution of Incompressible Flow Problems using Uintah and hypre,” SCI Technical Report, No. UUSCI-2012-002, SCI Institute, University of Utah, 2012.
The Uintah Software framework was developed to provide an environment for solving fluid-structure interaction problems on structured adaptive grids on large-scale, long-running, data-intensive problems. Uintah uses a combination of fluid-flow solvers and particle-based methods for solids together with a novel asynchronous task-based approach with fully automated load balancing. As Uintah is often used to solve compressible, low-Mach combustion applications, it is important to have a scalable linear solver. While there are many such solvers available, the scalability of those codes varies greatly. The hypre software offers a range of solvers and pre-conditioners for different types of grids. The weak scalability of Uintah and hypre is addressed for particular examples when applied to an incompressible flow problem relevant to combustion applications. After careful software engineering to reduce start-up costs, much better than expected weak scalability is seen for up to 100K cores on NSFs Kraken architecture and up to 200K+ cores, on DOEs new Titan machine.
Keywords: uintah, csafe
2011
![]()
D.E. Hart, M. Berzins, C.E. Goodyer, P.K. Jimack.
“Using Adjoint Error Estimation Techniques for Elastohydrodynamic Lubrication Line Contact Problems,” In International Journal for Numerical Methods in Fluids, Vol. 67, Note: Published online 29 October, pp. 1559--1570. 2011.
![]()
J. Luitjens, M. Berzins.
“Scalable parallel regridding algorithms for block-structured adaptive mesh renement,” In Concurrency And Computation: Practice And Experience, Vol. 23, No. 13, John Wiley & Sons, Ltd., pp. 1522--1537. 2011.
ISSN: 1532--0634
DOI: 10.1002/cpe.1719
![]()
J. Luitjens, M. Berzins.
“Scalable parallel regridding algorithms for block-structured adaptive mesh refinement,” In Concurrency and Computation: Practice and Experience, Vol. 23, No. 13, pp. 1522--1537. September, 2011.
DOI: 10.1002/cpe.1719
Block-structured adaptive mesh refinement (BSAMR) is widely used within simulation software because it improves the utilization of computing resources by refining the mesh only where necessary. For BSAMR to scale onto existing petascale and eventually exascale computers all portions of the simulation need to weak scale ideally. Any portions of the simulation that do not will become a bottleneck at larger numbers of cores. The challenge is to design algorithms that will make it possible to avoid these bottlenecks on exascale computers. One step of existing BSAMR algorithms involves determining where to create new patches of refinement. The Berger–Rigoutsos algorithm is commonly used to perform this task. This paper provides a detailed analysis of the performance of two existing parallel implementations of the Berger– Rigoutsos algorithm and develops a new parallel implementation of the Berger–Rigoutsos algorithm and a tiled algorithm that exhibits ideal scalability. The analysis and computational results up to 98 304 cores are used to design performance models which are then used to predict how these algorithms will perform on 100 M cores.
![]()
Q. Meng, M. Berzins, J. Schmidt.
“Using Hybrid Parallelism to improve memory use in Uintah,” In Proceedings of the TeraGrid 2011 Conference, Salt Lake City, Utah, ACM, July, 2011.
DOI: 10.1145/2016741.2016767
The Uintah Software framework was developed to provide an environment for solving fluid-structure interaction problems on structured adaptive grids on large-scale, long-running, data-intensive problems. Uintah uses a combination of fluid-flow solvers and particle-based methods for solids together with a novel asynchronous task-based approach with fully automated load balancing. Uintah's memory use associated with ghost cells and global meta-data has become a barrier to scalability beyond O(100K) cores. A hybrid memory approach that addresses this issue is described and evaluated. The new approach based on a combination of Pthreads and MPI is shown to greatly reduce memory usage as predicted by a simple theoretical model, with comparable CPU performance.
Keywords: Uintah, C-SAFE, parallel computing
![]()
L.T. Tran, M. Berzins.
“IMPICE Method for Compressible Flow Problems in Uintah,” In International Journal For Numerical Methods In Fluids, Note: Published online 20 July, 2011.
![]()
L.T. Tran, M. Berzins.
“Defect Sampling in Global Error Estimation for ODEs and Method-Of-Lines PDEs Using Adjoint Methods,” SCI Technical Report, No. UUSCI-2011-006, SCI Institute, University of Utah, 2011.
2010
![]()
M. Berzins, J. Luitjens, Q. Meng, T. Harman, C.A. Wight, J.R. Peterson.
“Uintah: A Scalable Framework for Hazard Analysis,” In Proceedings of the Teragrid 2010 Conference, TG 10, Note: Awarded Best Paper in the Science Track!, pp. (published online). July, 2010.
ISBN: 978-1-60558-818-6
DOI: 10.1145/1838574.1838577
The Uintah Software system was developed to provide an environment for solving a fluid-structure interaction problems on structured adaptive grids on large-scale, long-running, data-intensive problems. Uintah uses a novel asynchronous task-based approach with fully automated load balancing. The application of Uintah to a petascale problem in hazard analysis arising from "sympathetic" explosions in which the collective interactions of a large ensemble of explosives results in dramatically increased explosion violence, is considered. The advances in scalability and combustion modeling needed to begin to solve this problem are discussed and illustrated by prototypical computational results.
Keywords: Uintah, csafe
![]()
M. Berzins.
“Nonlinear Data-Bounded Polynomial Approximations and their Applications in ENO Methods,” In Numerical Algorithms, Vol. 55, No. 2, pp. 171. 2010.
![]()
J. Luitjens, M. Berzins.
“Improving the Performance of Uintah: A Large-Scale Adaptive Meshing Computational Framework,” In Proceedings of the 24th IEEE International Parallel and Distributed Processing Symposium (IPDPS10), Atlanta, GA, pp. 1--10. 2010.
DOI: 10.1109/IPDPS.2010.5470437
Uintah is a highly parallel and adaptive multi-physics framework created by the Center for Simulation of Accidental Fires and Explosions in Utah. Uintah, which is built upon the Common Component Architecture, has facilitated the simulation of a wide variety of fluid-structure interaction problems using both adaptive structured meshes for the fluid and particles to model solids. Uintah was originally designed for, and has performed well on, about a thousand processors. The evolution of Uintah to use tens of thousands processors has required improvements in memory usage, data structure design, load balancing algorithms and cost estimation in order to improve strong and weak scalability up to 98,304 cores for situations in which the mesh used varies adaptively and also cases in which particles that represent the solids move from mesh cell to mesh cell.
Keywords: csafe, c-safe, scirun, uintah, fires, explosions, simulation
![]()
Q. Meng, J. Luitjens, M. Berzins.
“Dynamic Task Scheduling for Scalable Parallel AMR in the Uintah Framework,” SCI Technical Report, No. UUSCI-2010-001, SCI Institute, University of Utah, 2010.
![]()
Q. Meng, J. Luitjens, M. Berzins.
“Dynamic Task Scheduling for the Uintah Framework,” In Proceedings of the 3rd IEEE Workshop on Many-Task Computing on Grids and Supercomputers (MTAGS10), pp. 1--10. 2010.
DOI: 10.1109/MTAGS.2010.5699431
Uintah is a computational framework for fluid-structure interaction problems using a combination of the ICE fluid flow algorithm, adaptive mesh refinement (AMR) and MPM particle methods. Uintah uses domain decomposition with a task-graph approach for asynchronous communication and automatic message generation. The Uintah software has been used for a decade with its original task scheduler that ran computational tasks in a predefined static order. In order to improve the performance of Uintah for petascale architecture, a new dynamic task scheduler allowing better overlapping of the communication and computation is designed and evaluated in this study. The new scheduler supports asynchronous, out-of-order scheduling of computational tasks by putting them in a distributed directed acyclic graph (DAG) and by isolating task memory and keeping multiple copies of task variables in a data warehouse when necessary. A new runtime system has been implemented with a two-stage priority queuing architecture to improve the scheduling efficiency. The effectiveness of this new approach is shown through an analysis of the performance of the software on large scale fluid-structure examples.
![]()
J. Schmidt, M. Berzins.
“Development of the Uintah Gateway for Fluid-Structure-Interaction Problems,” In Proceedings of the Teragrid 2010 Conference, ACM, 2010.
DOI: 10.1145/1838574.1838591
![]()
M. Steffen, R.M. Kirby, M. Berzins.
“Decoupling and Balancing of Space and Time Errors in the Material Point Method (MPM),” In International Journal for Numerical Methods in Engineering, Vol. 82, No. 10, pp. 1207--1243. 2010.
Page 5 of 13