
SCI Publications
2017
![]()
C. Gritton, J. Guilkey, J. Hooper, D. Bedrov, R. M. Kirby, M. Berzins.
“Using the material point method to model chemical/mechanical coupling in the deformation of a silicon anode,” In Modelling and Simulation in Materials Science and Engineering, Vol. 25, No. 4, pp. 045005. 2017.
The lithiation and delithiation of a silicon battery anode is modeled using the material point method (MPM). The main challenges in modeling this process using the MPM is to simulate stress dependent diffusion coupled with concentration dependent stress within a material that undergoes large deformations. MPM is chosen as the numerical method of choice because of its ability to handle large deformations. A method for modeling diffusion within MPM is described. A stress dependent model for diffusivity and three different constitutive models that fully couple the equations for stress with the equations for diffusion are considered. Verifications tests for the accuracy of the numerical implementations of the models and validation tests with experimental results show the accuracy of the approach. The application of the fully coupled stress diffusion model implemented in MPM is applied to modeling the lithiation and delithiation of silicon nanopillars.
![]()
J. K. Holmen, A. Humphrey, D. Sutherland, M. Berzins.
“Improving Uintah's Scalability Through the Use of Portable Kokkos-Based Data Parallel Tasks,” In Proceedings of the Practice and Experience in Advanced Research Computing 2017 on Sustainability, Success and Impact, PEARC17, No. 27, pp. 27:1--27:8. 2017.
ISBN: 978-1-4503-5272-7
DOI: 10.1145/3093338.3093388
The University of Utah's Carbon Capture Multidisciplinary Simulation Center (CCMSC) is using the Uintah Computational Framework to predict performance of a 1000 MWe ultra-supercritical clean coal boiler. The center aims to utilize the Intel Xeon Phi-based DOE systems, Theta and Aurora, through the Aurora Early Science Program by using the Kokkos C++ library to enable node-level performance portability. This paper describes infrastructure advancements and portability improvements made possible by our integration of Kokkos within Uintah. Scalability results are presented that compare serial and data parallel task execution models for a challenging radiative heat transfer calculation, central to the center's predictive boiler simulations. These results demonstrate both good strong-scaling characteristics to 256 Knights Landing (KNL) processors on the NSF Stampede system, and show the KNL-based calculation to compete with prior GPU-based results for the same calculation.
![]()
T.A.J. Ouermi, A. Knoll, R.M. Kirby, M. Berzins.
“OpenMP 4 Fortran Modernization of WSM6 for KNL,” In Proceedings of the Practice and Experience in Advanced Research Computing 2017 on Sustainability, Success and Impact, PEARC17, No. 12, ACM, pp. 12:1--12:8. 2017.
ISBN: 978-1-4503-5272-7
DOI: 10.1145/3093338.3093387
Parallel code portability in the petascale era requires modifying existing codes to support new architectures with large core counts and SIMD vector units. OpenMP is a well established and increasingly supported vehicle for portable parallelization. As architectures mature and compiler OpenMP implementations evolve, best practices for code modernization change as well. In this paper, we examine the impact of newer OpenMP features (in particular OMP SIMD) on the Intel Xeon Phi Knights Landing (KNL) architecture, applied in optimizing loops in the single moment 6-class microphysics module (WSM6) in the US Navy's NEPTUNE code. We find that with functioning OMP SIMD constructs, low thread invocation overhead on KNL and reduced penalty for unaligned access compared to previous architectures, one can leverage OpenMP 4 to achieve reasonable scalability with relatively minor reorganization of a production physics code.
![]()
T.A.J. Ouermi, A. Knoll, R.M. Kirby, M. Berzins.
“Optimization Strategies for WRF Single-Moment 6-Class Microphysics Scheme (WSM6) on Intel Microarchitectures,” In Proceedings of the fifth international symposium on computing and networking (CANDAR 17). Awarded Best Paper , IEEE, 2017.
Optimizations in the petascale era require modifications of existing codes to take advantage of new architectures with large core counts and SIMD vector units. This paper examines high-level and low-level optimization strategies for numerical weather prediction (NWP) codes. These strategies employ thread-local structures of arrays (SOA) and an OpenMP directive such as OMP SIMD. These optimization approaches are applied to the Weather Research Forecasting single-moment 6-class microphysics schemes (WSM6) in the US Navy NEPTUNE system. The results of this study indicate that the high-level approach with SOA and low-level OMP SIMD improves thread and vector parallelism by increasing data and temporal locality. The modified version of WSM6 runs 70x faster than the original serial code. This improvement is about 23.3x faster than the performance achieved by Ouermi et al., and 14.9x faster than the performance achieved by Michalakes et al.
![]()
B. Peterson, A. Humphrey, J. Schmidt, M. Berzins.
“Addressing Global Data Dependencies in Heterogeneous Asynchronous Runtime Systems on GPUs. Awarded Best Paper,” In Proceedings of the Third International Workshop on Extreme Scale Programming Models and Middleware - ESPM2'17, ACM, 2017.
DOI: 10.1145/3152041.3152082
Large-scale parallel applications with complex global data dependencies beyond those of reductions pose significant scalability challenges in an asynchronous runtime system. Internodal challenges include identifying the all-to-all communication of data dependencies among the nodes. Intranodal challenges include gathering together these data dependencies into usable data objects while avoiding data duplication. This paper addresses these challenges within the context of a large-scale, industrial coal boiler simulation using the Uintah asynchronous many-task runtime system on GPU architectures. We show significant reduction in time spent analyzing data dependencies through refinements in our dependency search algorithm. Multiple task graphs are used to eliminate subsequent analysis when task graphs change in predictable and repeatable ways. Using a combined data store and task scheduler redesign reduces data dependency duplication ensuring that problems fit within host and GPU memory. These modifications did not require any changes to application code or sweeping changes to the Uintah runtime system. We report results running on the DOE Titan system on 119K CPU cores and 7.5K GPUs simultaneously. Our solutions can be generalized to other task dependency problems with global dependencies among thousands of nodes which must be processed efficiently at large scale.
2016
![]()
J. Beckvermit, T. Harman, C. Wight, M. Berzins.
“Physical Mechanisms of DDT in an Array of PBX 9501 Cylinders Initiation Mechanisms of DDT,” SCI Institute, April, 2016.
The Deflagration to Detonation Transition (DDT) in large arrays (100s) of explosive devices is investigated using large-scale computer simulations running the Uintah Computational Framework. Our particular interest is understanding the fundamental physical mechanisms by which convective deflagration of cylindrical PBX 9501 devices can transition to a fully-developed detonation in transportation accidents. The simulations reveal two dominant mechanisms, inertial confinement and Impact to Detonation Transition. In this study we examined the role of physical spacing of the cylinders and how it influenced the initiation of DDT.
![]()
J. Beckvermit, T. Harman, C. Wight,, M. Berzins.
“Packing Configurations of PBX-9501 Cylinders to Reduce the Probability of a Deflagration to Detonation Transition (DDT),” In Propellants, Explosives, Pyrotechnics, 2016.
ISSN: 1521-4087
DOI: 10.1002/prep.201500331
The detonation of hundreds of explosive devices from either a transportation or storage accident is an extremely dangerous event. This paper focuses on identifying ways of packing/storing arrays of explosive cylinders that will reduce the probability of a Deflagration to Detonation Transition (DDT). The Uintah Computational Framework was utilized to predict the conditions necessary for a large scale DDT to occur. The results showed that the arrangement of the explosive cylinders and the number of devices packed in a "box" greatly effects the probability of a detonation.
![]()
M. Berzins, J. Beckvermit, T. Harman, A. Bezdjian, A. Humphrey, Q. Meng, J. Schmidt,, C. Wight.
“Extending the Uintah Framework through the Petascale Modeling of Detonation in Arrays of High Explosive Devices,” In SIAM Journal on Scientific Computing , Vol. 38, No. 5, pp. S101-S122. 2016.
DOI: 10.1137/15M1023270
The Uintah framework for solving a broad class of fluid-structure interaction problems uses a layered taskgraph approach that decouples the problem specification as a set of tasks from the adaptove runtime system that executes these tasks. Uintah has been developed by using a problem-driven approach that dates back to its inception. Using this approach it is possible to improve the performance of the problem-independent software components to enable the solution of broad classes of problems as well as the driving problem itself. This process is illustrated by a motivating problem that is the computational modeling of the hazards posed by thousands of explosive devices during a Deflagration to Detonation Transition (DDT) that occurred on Highway 6 in Utah. In order to solve this complex fluid-structure interaction problem at the required scale, algorithmic and data structure improvements were needed in a code that already appeared to work well at scale. These transformations enabled scalable runs for our target problem and provided the capability to model the transition to detonation. The performance improvements achieved are shown and the solution to the target problem provides insight as to why the detonation happened, as well as to a possible remediation strategy.
![]()
C. Gritton, M. Berzins.
“Improving accuracy in the MPM method using a null space filter,” In Computational Particle Mechanics, pp. 1--12. 2016.
ISSN: 2196-4386
DOI: 10.1007/s40571-016-0134-3
The material point method (MPM) has been very successful in providing solutions to many challenging problems involving large deformations. Nevertheless there are some important issues that remain to be resolved with regard to its analysis. One key challenge applies to both MPM and particle-in-cell (PIC) methods and arises from the difference between the number of particles and the number of the nodal grid points to which the particles are mapped. This difference between the number of particles and the number of grid points gives rise to a non-trivial null space of the linear operator that maps particle values onto nodal grid point values. In other words, there are non-zero particle values that when mapped to the grid point nodes result in a zero value there. Moreover, when the nodal values at the grid points are mapped back to particles, part of those particle values may be in that same null space. Given positive mapping weights from particles to nodes such null space values are oscillatory in nature. While this problem has been observed almost since the beginning of PIC methods there are still elements of it that are problematical today as well as methods that transcend it. The null space may be viewed as being connected to the ringing instability identified by Brackbill for PIC methods. It will be shown that it is possible to remove these null space values from the solution using a null space filter. This filter improves the accuracy of the MPM methods using an approach that is based upon a local singular value decomposition (SVD) calculation. This local SVD approach is compared against the global SVD approach previously considered by the authors and to a recent MPM method by Zhang and colleagues.
![]()
A. Humphrey, D. Sunderland, T. Harman, M. Berzins.
“Radiative Heat Transfer Calculation on 16384 GPUs Using a Reverse Monte Carlo Ray Tracing Approach with Adaptive Mesh Refinement,” In 2016 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), pp. 1222-1231. May, 2016.
DOI: 10.1109/IPDPSW.2016.93
Modeling thermal radiation is computationally challenging in parallel due to its all-to-all physical and resulting computational connectivity, and is also the dominant mode of heat transfer in practical applications such as next-generation clean coal boilers, being modeled by the Uintah framework. However, a direct all-to-all treatment of radiation is prohibitively expensive on large computers systems whether homogeneous or heterogeneous. DOE Titan and the planned DOE Summit and Sierra machines are examples of current and emerging GPUbased heterogeneous systems where the increased processing capability of GPUs over CPUs exacerbates this problem. These systems require that computational frameworks like Uintah leverage an arbitrary number of on-node GPUs, while simultaneously utilizing thousands of GPUs within a single simulation. We show that radiative heat transfer problems can be made to scale within Uintah on heterogeneous systems through a combination of reverse Monte Carlo ray tracing (RMCRT) techniques combined with AMR, to reduce the amount of global communication. In particular, significant Uintah infrastructure changes, including a novel lock and contention-free, thread-scalable data structure for managing MPI communication requests and improved memory allocation strategies were necessary to achieve excellent strong scaling results to 16384 GPUs on Titan.
![]()
D. Sunderland, B. Peterson, J. Schmidt, A. Humphrey, J. Thornock,, M. Berzins.
“An Overview of Performance Portability in the Uintah Runtime System Through the Use of Kokkos,” In Proceedings of the Second Internationsl Workshop on Extreme Scale Programming Models and Middleware, Salt Lake City, Utah, ESPM2, IEEE Press, Piscataway, NJ, USA pp. 44--47. 2016.
ISBN: 978-1-5090-3858-9
DOI: 10.1109/ESPM2.2016.10
The current diversity in nodal parallel computer architectures is seen in machines based upon multicore CPUs, GPUs and the Intel Xeon Phi's. A class of approaches for enabling scalability of complex applications on such architectures is based upon Asynchronous Many Task software architectures such as that in the Uintah framework used for the parallel solution of solid and fluid mechanics problems. Uintah has both an applications layer with its own programming model and a separate runtime system. While Uintah scales well today, it is necessary to address nodal performance portability in order for it to continue to do. Incrementally modifying Uintah to use the Kokkos performance portability library through prototyping experiments results in improved kernel performance by more than a factor of two.
![]()
D. Sunderland, B. Peterson, J. Schmidt, A. Humphrey, J. Thornock, M. Berzins.
“An Overview of Performance Portability in the Uintah Runtime System through the Use of Kokkos,” In 2016 Second International Workshop on Extreme Scale Programming Models and Middlewar (ESPM2), IEEE, Nov, 2016.
DOI: 10.1109/espm2.2016.012
The current diversity in nodal parallel computer architectures is seen in machines based upon multicore CPUs, GPUs and the Intel Xeon Phi's. A class of approaches for enabling scalability of complex applications on such architectures is based upon Asynchronous Many Task software architectures such as that in the Uintah framework used for the parallel solution of solid and fluid mechanics problems. Uintah has both an applications layer with its own programming model and a separate runtime system. While Uintah scales well today, it is necessary to address nodal performance portability in order for it to continue to do. Incrementally modifying Uintah to use the Kokkos performance portability library through prototyping experiments results in improved kernel performance by more than a factor of two.
2015
![]()
J. Bennett, R. Clay, G. Baker, M. Gamell, D. Hollman, S. Knight, H. Kolla, G. Sjaardema, N. Slattengren, K. Teranishi, J. Wilke, M. Bettencourt, S. Bova, K. Franko, P. Lin, R. Grant, S. Hammond, S. Olivier, L. Kale, N. Jain, E. Mikida, A. Aiken, M. Bauer, W. Lee, E. Slaughter, S. Treichler, M. Berzins, T. Harman, A. Humphrey, J. Schmidt, D. Sunderland, P. McCormick, S. Gutierrez, M. Schulz, A. Bhatele, D. Boehme, P. Bremer, T. Gamblin.
“ASC ATDM level 2 milestone #5325: Asynchronous many-task runtime system analysis and assessment for next generation platforms,” Sandia National Laboratories, 2015.
This report provides in-depth information and analysis to help create a technical road map for developing nextgeneration programming models and runtime systems that support Advanced Simulation and Computing (ASC) workload requirements. The focus herein is on asynchronous many-task (AMT) model and runtime systems, which are of great interest in the context of "exascale" computing, as they hold the promise to address key issues associated with future extreme-scale computer architectures. This report includes a thorough qualitative and quantitative examination of three best-of-class AMT runtime systems—Charm++, Legion, and Uintah, all of which are in use as part of the ASC Predictive Science Academic Alliance Program II (PSAAP-II) Centers. The studies focus on each of the runtimes' programmability, performance, and mutability. Through the experiments and analysis presented, several overarching findings emerge. From a performance perspective, AMT runtimes show tremendous potential for addressing extremescale challenges. Empirical studies show an AMT runtime can mitigate performance heterogeneity inherent to the machine itself and that Message Passing Interface (MPI) and AMT runtimes perform comparably under balanced conditions. From a programmability and mutability perspective however, none of the runtimes in this study are currently ready for use in developing production-ready Sandia ASC applications. The report concludes by recommending a codesign path forward, wherein application, programming model, and runtime system developers work together to define requirements and solutions. Such a requirements-driven co-design approach benefits the high-performance computing (HPC) community as a whole, with widespread community engagement mitigating risk for both application developers and runtime system developers.
![]()
C. Gritton, M. Berzins, R. M. Kirby.
“Improving Accuracy In Particle Methods Using Null Spaces and Filters,” In Proceedings of the IV International Conference on Particle-Based Methods - Fundamentals and Applications, Barcelona, Spain, Edited by E. Onate and M. Bischoff and D.R.J. Owen and P. Wriggers and T. Zohdi, CIMNE, pp. 202-213. September, 2015.
ISBN: 978-84-944244-7-2
While particle-in-cell type methods, such as MPM, have been very successful in providing solutions to many challenging problems there are some important issues that remain to be resolved with regard to their analysis. One such challenge relates to the difference in dimensionality between the particles and the grid points to which they are mapped. There exists a non-trivial null space of the linear operator that maps particles values onto nodal values. In other words, there are non-zero particle values values that when mapped to the nodes are zero there. Given positive mapping weights such null space values are oscillatory in nature. The null space may be viewed as a more general form of the ringing instability identified by Brackbill for PIC methods. It will be shown that it is possible to remove these null-space values from the solution and so to improve the accuracy of PIC methods, using a matrix SVD approach. The expense of doing this is prohibitive for real problems and so a local method is developed for doing this.
![]()
J. K. Holmen, A. Humphrey, M. Berzins.
“Exploring Use of the Reserved Core,” In High Performance Parallelism Pearls, Edited by J. Reinders and J. Jeffers, Elsevier, pp. 229-242. 2015.
DOI: 10.1016/b978-0-12-803819-2.00010-0
In this chapter, we illustrate benefits of thinking in terms of thread management techniques when using a centralized scheduler model along with interoperability of MPI and PThreads. This is facilitated through an exploration of thread placement strategies for an algorithm modeling radiative heat transfer with special attention to the 61st core. This algorithm plays a key role within the Uintah Computational Framework (UCF) and current efforts taking place at the University of Utah to model next-generation, large-scale clean coal boilers. In such simulations, this algorithm models the dominant form of heat transfer and consumes a large portion of compute time. Exemplified by a real-world example, this chapter presents our early efforts in porting a key portion of a scalability-centric codebase to the Intel ® Xeon PhiTM coprocessor. Specifically, this chapter presents results from our experiments profiling the native execution of a reverse Monte-Carlo ray tracing-based radiation model on a single coprocessor. These results demonstrate that our fastest run confiurations utilized the 61st core and that performance was not profoundly impacted when explicitly over-subscribing the coprocessor operating system thread. Additionally, this chapter presents a portion of radiation model source code, a MIC-centric UCF cross-compilation example, and less conventional thread management techniques for developers utilizing the PThreads threading model.
![]()
A. Humphrey, T. Harman, M. Berzins, P. Smith.
“A Scalable Algorithm for Radiative Heat Transfer Using Reverse Monte Carlo Ray Tracing,” In High Performance Computing, Lecture Notes in Computer Science, Vol. 9137, Edited by Kunkel, Julian M. and Ludwig, Thomas, Springer International Publishing, pp. 212-230. 2015.
ISBN: 978-3-319-20118-4
DOI: 10.1007/978-3-319-20119-1_16
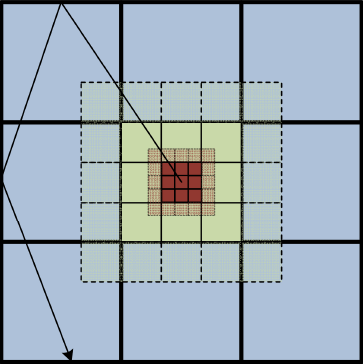
Keywords: Uintah; Radiation modeling; Parallel; Scalability; Adaptive mesh refinement; Simulation science; Titan
R.M. Kirby, M. Berzins, J.S. Hesthaven (Editors).
“Spectral and High Order Methods for Partial Differential Equations,” Subtitled “Selected Papers from the ICOSAHOM'14 Conference, June 23-27, 2014, Salt Lake City, UT, USA.,” In Lecture Notes in Computational Science and Engineering, Springer, 2015.
![]()
B. Peterson, N. Xiao, J. Holmen, S. Chaganti, A. Pakki, J. Schmidt, D. Sunderland, A. Humphrey, M. Berzins.
“Developing Uintah’s Runtime System For Forthcoming Architectures,” Subtitled “Refereed paper presented at the RESPA 15 Workshop at SuperComputing 2015 Austin Texas,” SCI Institute, 2015.
![]()
B. Peterson, H. K. Dasari, A. Humphrey, J.C. Sutherland, T. Saad, M. Berzins.
“Reducing overhead in the Uintah framework to support short-lived tasks on GPU-heterogeneous architectures,” In Proceedings of the 5th International Workshop on Domain-Specific Languages and High-Level Frameworks for High Performance Computing (WOLFHPC'15), ACM, pp. 4:1-4:8. 2015.
DOI: 10.1145/2830018.2830023
![]()
D. Reed, M. Berzins, R. Lucas, S. Matsuoka, R. Pennington, V. Sarkar, V. Taylor.
“DOE Advanced Scientific Computing Advisory Committee (ASCAC) Report: Exascale Computing Initiative Review,” Note: DOE Report, 2015.
DOI: DOI 10.2172/1222712
Page 3 of 13