
SCI Publications
2014
![]()
A. Dubey, A. Almgren, John Bell, M. Berzins, S. Brandt, G. Bryan, P. Colella, D. Graves, M. Lijewski, F. Löffler, B. O’Shea, E. Schnetter, B. Van Straalen, K. Weide.
“A survey of high level frameworks in block-structured adaptive mesh refinement packages,” In Journal of Parallel and Distributed Computing, 2014.
DOI: 10.1016/j.jpdc.2014.07.001
Over the last decade block-structured adaptive mesh refinement (SAMR) has found increasing use in large, publicly available codes and frameworks. SAMR frameworks have evolved along different paths. Some have stayed focused on specific domain areas, others have pursued a more general functionality, providing the building blocks for a larger variety of applications. In this survey paper we examine a representative set of SAMR packages and SAMR-based codes that have been in existence for half a decade or more, have a reasonably sized and active user base outside of their home institutions, and are publicly available. The set consists of a mix of SAMR packages and application codes that cover a broad range of scientific domains. We look at their high-level frameworks, their design trade-offs and their approach to dealing with the advent of radical changes in hardware architecture. The codes included in this survey are BoxLib, Cactus, Chombo, Enzo, FLASH, and Uintah.
Keywords: SAMR, BoxLib, Chombo, FLASH, Cactus, Enzo, Uintah
![]()
Z. Fu, H.K. Dasari, M. Berzins, B. Thompson.
“Parallel Breadth First Search on GPU Clusters,” SCI Technical Report, No. UUSCI-2014-002, SCI Institute, University of Utah, 2014.
Fast, scalable, low-cost, and low-power execution of parallel graph algorithms is important for a wide variety of commercial and public sector applications. Breadth First Search (BFS) imposes an extreme burden on memory bandwidth and network communications and has been proposed as a benchmark that may be used to evaluate current and future parallel computers. Hardware trends and manufacturing limits strongly imply that many core devices, such as NVIDIA® GPUs and the Intel® Xeon Phi®, will become central components of such future systems. GPUs are well known to deliver the highest FLOPS/watt and enjoy a very significant memory bandwidth advantage over CPU architectures. Recent work has demonstrated that GPUs can deliver high performance for parallel graph algorithms and, further, that it is possible to encapsulate that capability in a manner that hides the low level details of the GPU architecture and the CUDA language but preserves the high throughput of the GPU. We extend previous research on GPUs and on scalable graph processing on super-computers and demonstrate that a high-performance parallel graph machine can be created using commodity GPUs and networking hardware.
Keywords: GPU cluster, MPI, BFS, graph, parallel graph algorithm
![]()
Z. Fu, H.K. Dasari, M. Berzins, B. Thompson.
“Parallel Breadth First Search on GPU Clusters,” In Proceedings of the IEEE BigData 2014 Conference, Washington DC, October, 2014.
Fast, scalable, low-cost, and low-power execution of parallel graph algorithms is important for a wide variety of commercial and public sector applications. Breadth First Search (BFS) imposes an extreme burden on memory bandwidth and network communications and has been proposed as a benchmark that may be used to evaluate current and future parallel computers. Hardware trends and manufacturing limits strongly imply that many core devices, such as NVIDIA® GPUs and the Intel® Xeon Phi®, will become central components of such future systems. GPUs are well known to deliver the highest FLOPS/watt and enjoy a very significant memory bandwidth advantage over CPU architectures. Recent work has demonstrated that GPUs can deliver high performance for parallel graph algorithms and, further, that it is possible to encapsulate that capability in a manner that hides the low level details of the GPU architecture and the CUDA language but preserves the high throughput of the GPU. We extend previous research on GPUs and on scalable graph processing on super-computers and demonstrate that a high-performance parallel graph machine can be created using commodity GPUs and networking hardware.
Keywords: GPU cluster, MPI, BFS, graph, parallel graph algorithm
![]()
A. Humphrey, Q. Meng, M. Berzins, D. Caminha B.de Oliveira, Z. Rakamaric, G. Gopalakrishnan.
“Systematic Debugging Methods for Large-Scale HPC Computational Frameworks,” In Computing in Science Engineering, Vol. 16, No. 3, pp. 48--56. May, 2014.
ISSN: 1521-9615
DOI: 10.1109/MCSE.2014.11

Keywords: Computational Modeling and Frameworks, Parallel Programming, Reliability, Debugging Aids
![]()
S. Kumar, C. Christensen, P.-T. Bremer, E. Brugger, V. Pascucci, J. Schmidt, M. Berzins, H. Kolla, J. Chen, V. Vishwanath, P. Carns, R. Grout.
“Fast Multi-Resolution Reads of Massive Simulation Datasets,” In Proceedings of the International Supercomputing Conference ISC'14, Leipzig, Germany, June, 2014.

![]()
Q. Meng, M. Berzins.
“Scalable large-scale fluid-structure interaction solvers in the Uintah framework via hybrid task-based parallelism algorithms,” In Concurrency and Computation: Practice and Experience, Vol. 26, No. 7, pp. 1388--1407. May, 2014.
DOI: 10.1002/cpe
Uintah is a software framework that provides an environment for solving fluid–structure interaction problems on structured adaptive grids for large-scale science and engineering problems involving the solution of partial differential equations. Uintah uses a combination of fluid flow solvers and particle-based methods for solids, together with adaptive meshing and a novel asynchronous task-based approach with fully automated load balancing. When applying Uintah to fluid–structure interaction problems, the combination of adaptive mesh- ing and the movement of structures through space present a formidable challenge in terms of achieving scalability on large-scale parallel computers. The Uintah approach to the growth of the number of core counts per socket together with the prospect of less memory per core is to adopt a model that uses MPI to communicate between nodes and a shared memory model on-node so as to achieve scalability on large-scale systems. For this approach to be successful, it is necessary to design data structures that large numbers of cores can simultaneously access without contention. This scalability challenge is addressed here for Uintah, by the development of new hybrid runtime and scheduling algorithms combined with novel lock-free data structures, making it possible for Uintah to achieve excellent scalability for a challenging fluid–structure problem with mesh refinement on as many as 260K cores.
Keywords: MPI, threads, Uintah, many core, lock free, fluid-structure interaction, c-safe
![]()
D.C.B. de Oliveira, A. Humphrey, Q. Meng, Z. Rakamaric, M. Berzins, G. Gopalakrishnan.
“Systematic Debugging of Concurrent Systems Using Coalesced Stack Trace Graphs,” In Proceedings of the 27th International Workshop on Languages and Compilers for Parallel Computing (LCPC), September, 2014.
A central need during software development of large-scale parallel systems is tools that help help to identify the root causes of bugs quickly. Given the massive scale of these systems, tools that highlight changes--say introduced across software versions or their operating conditions (e.g., inputs, schedules)--can prove to be highly effective in practice. Conventional debuggers, while good at presenting details at the problem-site (e.g., crash), often omit contextual information to identify the root causes of the bug. We present a new approach to collect and coalesce stack traces, leading to an efficient summary display of salient system control flow differences in a graphical form called Coalesced Stack Trace Graphs (CSTG). CSTGs have helped us understand and debug situations within a computational framework called Uintah that has been deployed at large scale, and undergoes frequent version updates. In this paper, we detail CSTGs through case studies in the context of Uintah where unexpected behaviors caused by different vesions of software or occurring across different time-steps of a system (e.g., due to non-determinism) are debugged. We show that CSTG also gives conventional debuggers a far more productive and guided role to play.
2013
![]()
J. Beckvermit, J. Peterson, T. Harman, S. Bardenhagen, C. Wight, Q. Meng, M. Berzins.
“Multiscale Modeling of Accidental Explosions and Detonations,” In Computing in Science and Engineering, Vol. 15, No. 4, pp. 76--86. 2013.
DOI: 10.1109/MCSE.2013.89

Accidental explosions are exceptionally dangerous and costly, both in lives and money. Regarding world-wide conflict with small arms and light weapons, the Small Arms Survey has recorded over 297 accidental explosions in munitions depots across the world that have resulted in thousands of deaths and billions of dollars in damage in the past decade alone [45]. As the recent fertilizer plant explosion that killed 15 people in West, Texas demonstrates, accidental explosions are not limited to military operations. Transportation accidents also pose risks, as illustrated by the occasional train derailment/explosion in the nightly news, or the semi-truck explosion detailed in the following section. Unlike other industrial accident scenarios, explosions can easily affect the general public, a dramatic example being the PEPCON disaster in 1988, where windows were shattered, doors blown off their hinges, and flying glass and debris caused injuries up to 10 miles away.
While the relative rarity of accidental explosions speaks well of our understanding to date, their violence rightly gives us pause. A better understanding of these materials is clearly still needed, but a significant barrier is the complexity of these materials and the various length scales involved. In typical military applications, explosives are known to be ignited by the coalescence of hot spots which occur on micrometer scales. Whether this reaction remains a deflagration (burning) or builds to a detonation depends both on the stimulus and the boundary conditions or level of confinement. Boundary conditions are typically on the scale of engineered parts, approximately meters. Additional dangers are present at the scale of trucks and factories. The interaction of various entities, such as barrels of fertilizer or crates of detonators, admits the possibility of a sympathetic detonation, i.e. the unintended detonation of one entity by the explosion of another, generally caused by an explosive shock wave or blast fragments.
While experimental work has been and will continue to be critical to developing our fundamental understanding of explosive initiation, de agration and detonation, there is no practical way to comprehensively assess safety on the scale of trucks and factories experimentally. The scenarios are too diverse and the costs too great. Numerical simulation provides a complementary tool that, with the steadily increasing computational power of the past decades, makes simulations at this scale begin to look plausible. Simulations at both the micrometer scale, the "mesoscale", and at the scale of engineered parts, the "macro-scale", have been contributing increasingly to our understanding of these materials. Still, simulations on this scale require both massively parallel computational infrastructure and selective sampling of mesoscale response, i.e. advanced computational tools and modeling. The computational framework Uintah [1] has been developed for exactly this purpose.
Keywords: uintah, c-safe, accidents, explosions, military computing, risk analysis
![]()
M. Berzins, J. Schmidt, Q. Meng, A. Humphrey.
“Past, Present, and Future Scalability of the Uintah Software,” In Proceedings of the Blue Waters Extreme Scaling Workshop 2012, pp. Article No.: 6. 2013.
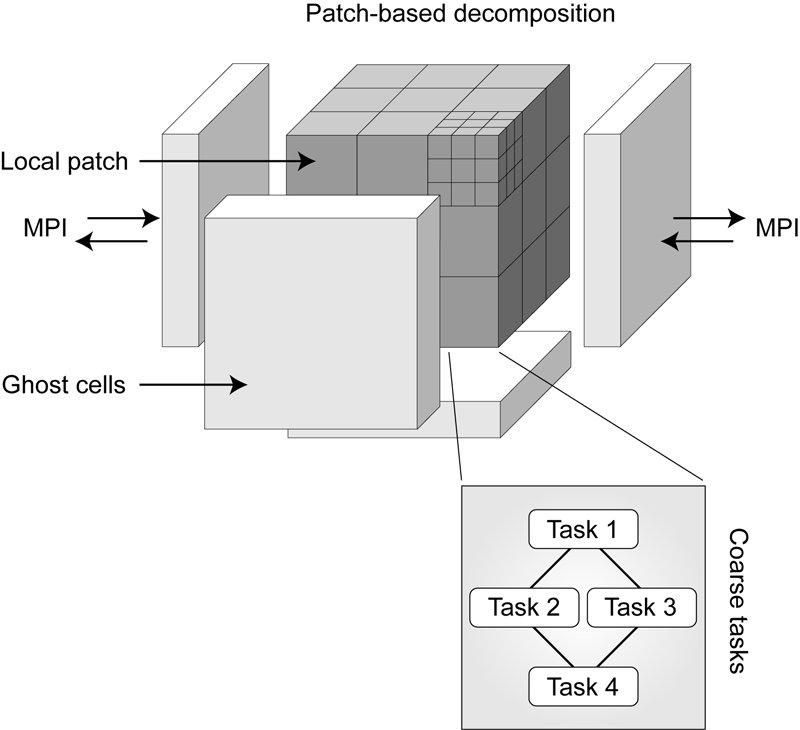
Keywords: netl, Uintah, parallelism, scalability, adaptive mesh refinement, linear equations
![]()
M. Berzins.
“Data and Range-Bounded Polynomials in ENO Methods,” In Journal of Computational Science, Vol. 4, No. 1-2, pp. 62--70. 2013.
DOI: 10.1016/j.jocs.2012.04.006
Essentially Non-Oscillatory (ENO) methods and Weighted Essentially Non-Oscillatory (WENO) methods are of fundamental importance in the numerical solution of hyperbolic equations. A key property of such equations is that the solution must remain positive or lie between bounds. A modification of the polynomials used in ENO methods to ensure that the modified polynomials are either bounded by adjacent values (data-bounded) or lie within a specified range (range-bounded) is considered. It is shown that this approach helps both in the range boundedness in the preservation of extrema in the ENO polynomial solution.
![]()
M. Hall, J.C. Beckvermit, C.A. Wight, T. Harman, M. Berzins.
“The influence of an applied heat flux on the violence of reaction of an explosive device,” In Proceedings of the Conference on Extreme Science and Engineering Discovery Environment: Gateway to Discovery, San Diego, California, XSEDE '13, pp. 11:1--11:8. 2013.
ISBN: 978-1-4503-2170-9
DOI: 10.1145/2484762.2484786
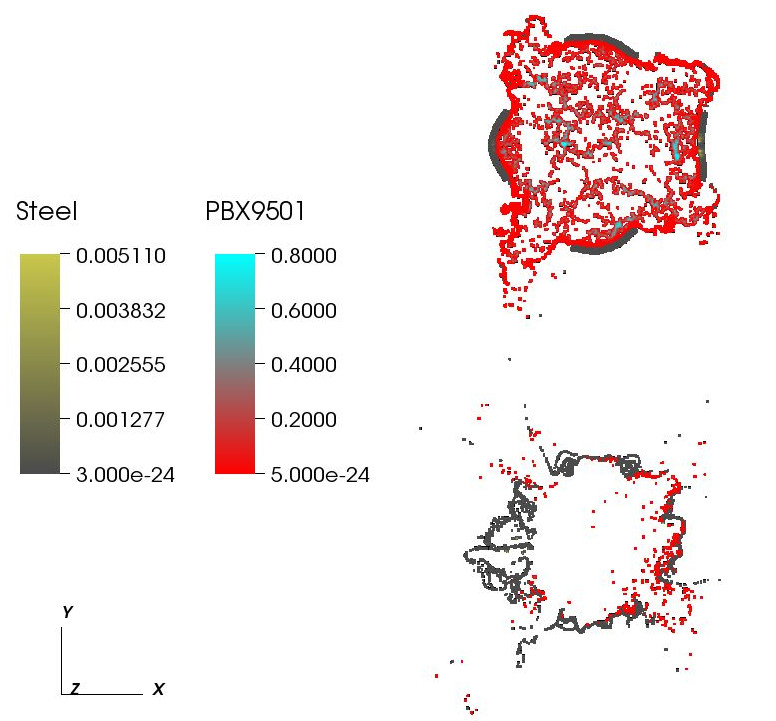
Keywords: DDT, cook-off, deflagration, detonation, violence of reaction, c-safe
![]()
Q. Meng, A. Humphrey, J. Schmidt, M. Berzins.
“Preliminary Experiences with the Uintah Framework on Intel Xeon Phi and Stampede,” SCI Technical Report, No. UUSCI-2013-002, SCI Institute, University of Utah, 2013.
In this work, we describe our preliminary experiences on the Stampede system in the context of the Uintah Computational Framework. Uintah was developed to provide an environment for solving a broad class of fluid-structure interaction problems on structured adaptive grids. Uintah uses a combination of fluid-flow solvers and particle-based methods, together with a novel asynchronous taskbased approach and fully automated load balancing. While we have designed scalable Uintah runtime systems for large CPU core counts, the emergence of heterogeneous systems presents considerable challenges in terms of effectively utilizing additional on-node accelerators and co-processors, deep memory hierarchies, as well as managing multiple levels of parallelism. Our recent work has addressed the emergence of heterogeneous CPU/GPU systems with the design of a Unified heterogeneous runtime system, enabling Uintah to fully exploit these architectures with support for asynchronous, out-of-order scheduling of both CPU and GPU computational tasks. Using this design, Uintah has run at full scale on the Keeneland System and TitanDev. With the release of the Intel Xeon Phi co-processor and the recent availability of the Stampede system, we show that Uintah may be modified to utilize such a coprocessor based system. We also explore the different usage models provided by the Xeon Phi with the aim of understanding portability of a general purpose framework like Uintah to this architecture. These usage models range from the pragma based offload model to the more complex symmetric model, utilizing all co-processor and host CPU cores simultaneously. We provide preliminary results of the various usage models for a challenging adaptive mesh refinement problem, as well as a detailed account of our experience adapting Uintah to run on the Stampede system. Our conclusion is that while the Stampede system is easy to use, obtaining high performance from the Xeon Phi co-processors requires a substantial but different investment to that needed for GPU-based systems.
Keywords: Uintah, hybrid parallelism, scalability, parallel, adaptive, MIC, Xeon Phi, heterogeneous systems, Stampede, co-processor
![]()
Q. Meng, A. Humphrey, J. Schmidt, M. Berzins.
“Investigating Applications Portability with the Uintah DAG-based Runtime System on PetaScale Supercomputers,” SCI Technical Report, No. UUSCI-2013-003, SCI Institute, University of Utah, 2013.
Present trends in high performance computing present formidable challenges for applications code using multicore nodes possibly with accelerators and/or co-processors and reduced memory while still attaining scalability. Software frameworks that execute machineindependent applications code using a runtime system that shields users from architectural complexities offer a possible solution. The Uintah framework for example, solves a broad class of large-scale problems on structured adaptive grids using fluid-flow solvers coupled with particle-based solids methods. Uintah executes directed acyclic graphs of computational tasks with a scalable asynchronous and dynamic runtime system for CPU cores and/or accelerators/coprocessors on a node. Uintah's clear separation between application and runtime code has led to scalability increases of 1000x without significant changes to application code. This methodology is tested on three leading Top500 machines; OLCF Titan, TACC Stampede and ALCF Mira using three diverse and challenging applications problems. This investigation of scalability with regard to the different processors and communications performance leads to the overall conclusion that the adaptive DAG-based approach provides a very powerful abstraction for solving challenging multiscale multi-physics engineering problems on some of the largest and most powerful computers available today.
Keywords: Uintah, hybrid parallelism, scalability, parallel, adaptive, MIC, Xeon Phi, heterogeneous systems, Stampede, co-processor
![]()
Q. Meng, A. Humphrey, J. Schmidt, M. Berzins.
“Investigating Applications Portability with the Uintah DAG-based Runtime System on PetaScale Supercomputers,” In Proceedings of SC13: International Conference for High Performance Computing, Networking, Storage and Analysis, pp. 96:1--96:12. 2013.
ISBN: 978-1-4503-2378-9
DOI: 10.1145/2503210.2503250
Present trends in high performance computing present formidable challenges for applications code using multicore nodes possibly with accelerators and/or co-processors and reduced memory while still attaining scalability. Software frameworks that execute machine-independent applications code using a runtime system that shields users from architectural complexities offer a possible solution. The Uintah framework for example, solves a broad class of large-scale problems on structured adaptive grids using fluid-flow solvers coupled with particle-based solids methods. Uintah executes directed acyclic graphs of computational tasks with a scalable asynchronous and dynamic runtime system for CPU cores and/or accelerators/co-processors on a node. Uintah's clear separation between application and runtime code has led to scalability increases of 1000x without significant changes to application code. This methodology is tested on three leading Top500 machines; OLCF Titan, TACC Stampede and ALCF Mira using three diverse and challenging applications problems. This investigation of scalability with regard to the different processors and communications performance leads to the overall conclusion that the adaptive DAG-based approach provides a very powerful abstraction for solving challenging multi-scale multi-physics engineering problems on some of the largest and most powerful computers available today.
Keywords: Blue Gene/Q, GPU, Xeon Phi, adaptive, application, co-processor, heterogeneous systems, hybrid parallelism, parallel, scalability, software, uintah, NETL
![]()
Q. Meng, A. Humphrey, J. Schmidt, M. Berzins.
“Preliminary Experiences with the Uintah Framework on Intel Xeon Phi and Stampede,” In Proceedings of the Conference on Extreme Science and Engineering Discovery Environment: Gateway to Discovery (XSEDE 2013), San Diego, California, pp. 48:1--48:8. 2013.
DOI: 10.1145/2484762.2484779
In this work, we describe our preliminary experiences on the Stampede system in the context of the Uintah Computational Framework. Uintah was developed to provide an environment for solving a broad class of fluid-structure interaction problems on structured adaptive grids. Uintah uses a combination of fluid-flow solvers and particle-based methods, together with a novel asynchronous task-based approach and fully automated load balancing. While we have designed scalable Uintah runtime systems for large CPU core counts, the emergence of heterogeneous systems presents considerable challenges in terms of effectively utilizing additional on-node accelerators and co-processors, deep memory hierarchies, as well as managing multiple levels of parallelism. Our recent work has addressed the emergence of heterogeneous CPU/GPU systems with the design of a Unified heterogeneous runtime system, enabling Uintah to fully exploit these architectures with support for asynchronous, out-of-order scheduling of both CPU and GPU computational tasks. Using this design, Uintah has run at full scale on the Keeneland System and TitanDev. With the release of the Intel Xeon Phi co-processor and the recent availability of the Stampede system, we show that Uintah may be modified to utilize such a co-processor based system. We also explore the different usage models provided by the Xeon Phi with the aim of understanding portability of a general purpose framework like Uintah to this architecture. These usage models range from the pragma based offload model to the more complex symmetric model, utilizing all co-processor and host CPU cores simultaneously. We provide preliminary results of the various usage models for a challenging adaptive mesh refinement problem, as well as a detailed account of our experience adapting Uintah to run on the Stampede system. Our conclusion is that while the Stampede system is easy to use, obtaining high performance from the Xeon Phi co-processors requires a substantial but different investment to that needed for GPU-based systems.
Keywords: MIC, Xeon Phi, adaptive, co-processor, heterogeneous systems, hybrid parallelism, parallel, scalability, stampede, uintah, c-safe
![]()
D.C.B. de Oliveira, Z. Rakamaric, G. Gopalakrishnan, A. Humphrey, Q. Meng, M. Berzins.
“Crash Early, Crash Often, Explain Well: Practical Formal Correctness Checking of Million-core Problem Solving Environments for HPC,” In Proceedings of the 35th International Conference on Software Engineering (ICSE 2013), pp. (accepted). 2013.
While formal correctness checking methods have been deployed at scale in a number of important practical domains, we believe that such an experiment has yet to occur in the domain of high performance computing at the scale of a million CPU cores. This paper presents preliminary results from the Uintah Runtime Verification (URV) project that has been launched with this objective. Uintah is an asynchronous task-graph based problem-solving environment that has shown promising results on problems as diverse as fluid-structure interaction and turbulent combustion at well over 200K cores to date. Uintah has been tested on leading platforms such as Kraken, Keenland, and Titan consisting of multicore CPUs and GPUs, incorporates several innovative design features, and is following a roadmap for development well into the million core regime. The main results from the URV project to date are crystallized in two observations: (1) A diverse array of well-known ideas from lightweight formal methods and testing/observing HPC systems at scale have an excellent chance of succeeding. The real challenges are in finding out exactly which combinations of ideas to deploy, and where. (2) Large-scale problem solving environments for HPC must be designed such that they can be \"crashed early\" (at smaller scales of deployment) and \"crashed often\" (have effective ways of input generation and schedule perturbation that cause vulnerabilities to be attacked with higher probability). Furthermore, following each crash, one must \"explain well\" (given the extremely obscure ways in which an error finally manifests itself, we must develop ways to record information leading up to the crash in informative ways, to minimize offsite debugging burden). Our plans to achieve these goals and to measure our success are described. We also highlight some of the broadly applicable concepts and approaches.
Keywords: Uintah
![]()
J.R. Peterson, C.A. Wight, M. Berzins.
“Applying high-performance computing to petascale explosive simulations,” In Procedia Computer Science, 2013.
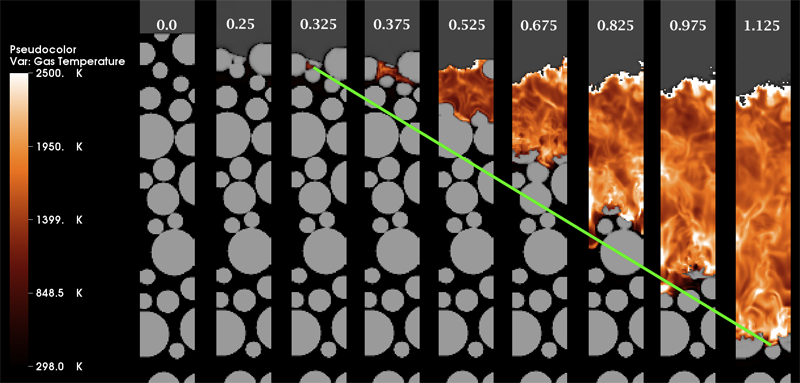
Keywords: Energetic Material Hazards, Uintah, MPM, ICE, MPMICE, Scalable Parallelism, C-SAFE
![]()
J. Schmidt, M. Berzins, J. Thornock, T. Saad, J. Sutherland.
“Large Scale Parallel Solution of Incompressible Flow Problems using Uintah and hypre,” In 2013 13th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (CCGrid), pp. 458--465. 2013.
The Uintah Software framework was developed to provide an environment for solving fluid-structure interaction problems on structured adaptive grids on large-scale, longrunning, data-intensive problems. Uintah uses a combination of fluid-flow solvers and particle-based methods for solids together with a novel asynchronous task-based approach with fully automated load balancing. As Uintah is often used to solve incompressible flow problems in combustion applications it is important to have a scalable linear solver. While there are many such solvers available, the scalability of those codes varies greatly. The hypre software offers a range of solvers and preconditioners for different types of grids. The weak scalability of Uintah and hypre is addressed for particular examples of both packages when applied to a number of incompressible flow problems. After careful software engineering to reduce startup costs, much better than expected weak scalability is seen for up to 100K cores on NSFs Kraken architecture and up to 260K cpu cores, on DOEs new Titan machine. The scalability is found to depend in a crtitical way on the choice of algorithm used by hypre for a realistic application problem.
Keywords: Uintah, hypre, parallelism, scalability, linear equations
2012
![]()
M. Berzins.
“Status of Release of the Uintah Computational Framework,” SCI Technical Report, No. UUSCI-2012-001, SCI Institute, University of Utah, 2012.
This report provides a summary of the status of the Uintah Computation Framework (UCF) software. Uintah is uniquely equipped to tackle large-scale multi-physics science and engineering problems on disparate length and time scales. The Uintah framework makes it possible to run adaptive computations on modern HPC architectures with tens and now hundreds of thousands of cores with complex communication/memory hierarchies. Uintah was orignally developed in the University of Utah Center for Simulation of Accidental Fires and Explosions (C-SAFE), a DOE-funded academic alliance project and then extended to the broader NSF snd DOE science and engineering communities. As Uintah is applicable to a wide range of engineering problems that involve fl uid-structure interactions with highly deformable structures it is used for a number of NSF-funded and DOE engineering projects. In this report the Uintah framework software is outlined and typical applications are illustrated. Uintah is open-source software that is available through the MIT open-source license at http://www.uintah.utah.edu/.
![]()
M. Berzins, Q. Meng, J. Schmidt, J.C. Sutherland.
“DAG-Based Software Frameworks for PDEs,” In Proceedings of Euro-Par 2011 Workshops, Part I, Lecture Notes in Computer Science (LNCS) 7155, Springer-Verlag Berlin Heidelberg, pp. 324--333. August, 2012.
The task-based approach to software and parallelism is well-known and has been proposed as a potential candidate, named the silver model, for exascale software. This approach is not yet widely used in the large-scale multi-core parallel computing of complex systems of partial differential equations. After surveying task-based approaches we investigate how well the Uintah software and an extension named Wasatch fit in the task-based paradigm and how well they perform on large scale parallel computers. The conclusion is that these approaches show great promise for petascale but that considerable algorithmic challenges remain.
Keywords: DOD, Uintah, CSAFE
Page 4 of 13