
SCI Publications
2020
![]()
M. Han, I. Wald, W. Usher, N. Morrical, A. Knoll, V. Pascucci, C.R. Johnson.
“A virtual frame buffer abstraction for parallel rendering of large tiled display walls,” In 2020 IEEE Visualization Conference (VIS), pp. 11--15. 2020.
DOI: 10.1109/VIS47514.2020.00009
We present dw2, a flexible and easy-to-use software infrastructure for interactive rendering of large tiled display walls. Our library represents the tiled display wall as a single virtual screen through a display "service", which renderers connect to and send image tiles to be displayed, either from an on-site or remote cluster. The display service can be easily configured to support a range of typical network and display hardware configurations; the client library provides a straightforward interface for easy integration into existing renderers. We evaluate the performance of our display wall service in different configurations using a CPU and GPU ray tracer, in both on-site and remote rendering scenarios using multiple display walls.
![]()
V. Pascucci, I. Altintas, J. Fortes, I. Foster, H. Gu, S. Hariri, D. Stanzione, M. Taufer, X. Zhao.
“Report from the NSF Workshop on Smart Cyberinfrastructure 2020,” NSF, 2020.
Machine learning and other Artifical Intelligenece technologies (all indicated in the following as AI) used within a modern, smart cyberinfrastructure have become critical new avenues for discovery and validation in data-driven science and engineering disciplines of all kinds. We can expect many landmark discoveries and new lines of productive research to be enabled through AI analysis of the rapidly growing treasure trove of scientific data. AI-based techniques have been applied in many fields of science and engineering, including remote sensing, cosmology, energy, cancer research, IT systems management, and machine design and control, but the lack of proper integration with the current NSF-supported cyberinfrastructure is limiting their potential. Recent events due to the COVID-19 pandemic have highlighted how cyberinfrastructure is a crucial enabler of modern research, with massive simulations and data management capabilities [8-10], but these events have also emphasized how the lack of proper integration with AI technology remains a major limiting factor for the advancement of science and engineering, especially when any kind of rapid response is needed.
2019
![]()
A. Gyulassy, P.-T. Bremer, V. Pascucci.
“Shared-Memory Parallel Computation of Morse-Smale Complexes with Improved Accuracy,” In IEEE Transactions on Visualization and Computer Graphics, Vol. 25, No. 1, IEEE, pp. 1183--1192. Jan, 2019.
DOI: 10.1109/tvcg.2018.2864848
Topological techniques have proven to be a powerful tool in the analysis and visualization of large-scale scientific data. In particular, the Morse-Smale complex and its various components provide a rich framework for robust feature definition and computation. Consequently, there now exist a number of approaches to compute Morse-Smale complexes for large-scale data in parallel. However, existing techniques are based on discrete concepts which produce the correct topological structure but are known to introduce grid artifacts in the resulting geometry. Here, we present a new approach that combines parallel streamline computation with combinatorial methods to construct a high-quality discrete Morse-Smale complex. In addition to being invariant to the orientation of the underlying grid, this algorithm allows users to selectively build a subset of features using high-quality geometry. In particular, a user may specifically select which ascending/descending manifolds are reconstructed with improved accuracy, focusing computational effort where it matters for subsequent analysis. This approach computes Morse-Smale complexes for larger data than previously feasible with significant speedups. We demonstrate and validate our approach using several examples from a variety of different scientific domains, and evaluate the performance of our method.
![]()
D. Hoang, P. Klacansky, H. Bhatia, P.-T. Bremer, P. Lindstrom, V. Pascucci.
“A Study of the Trade-off Between Reducing Precision and Reducing Resolution for Data Analysis and Visualization,” In IEEE Transactions on Visualization and Computer Graphics, Vol. 25, No. 1, IEEE, pp. 1193--1203. Jan, 2019.
DOI: 10.1109/tvcg.2018.2864853
There currently exist two dominant strategies to reduce data sizes in analysis and visualization: reducing the precision of the data, e.g., through quantization, or reducing its resolution, e.g., by subsampling. Both have advantages and disadvantages and both face fundamental limits at which the reduced information ceases to be useful. The paper explores the additional gains that could be achieved by combining both strategies. In particular, we present a common framework that allows us to study the trade-off in reducing precision and/or resolution in a principled manner. We represent data reduction schemes as progressive streams of bits and study how various bit orderings such as by resolution, by precision, etc., impact the resulting approximation error across a variety of data sets as well as analysis tasks. Furthermore, we compute streams that are optimized for different tasks to serve as lower bounds on the achievable error. Scientific data management systems can use the results presented in this paper as guidance on how to store and stream data to make efficient use of the limited storage and bandwidth in practice.
![]()
W. Usher, I. Wald, J. Amstutz, J. Gunther, C. Brownlee, V. Pascucci.
“Scalable Ray Tracing Using the Distributed FrameBuffer,” In Eurographics Conference on Visualization (EuroVis) 2019, Vol. 38, No. 3, 2019.
Image- and data-parallel rendering across multiple nodes on high-performance computing systems is widely used in visualization to provide higher frame rates, support large data sets, and render data in situ. Specifically for in situ visualization, reducing bottlenecks incurred by the visualization and compositing is of key concern to reduce the overall simulation runtime. Moreover, prior algorithms have been designed to support either image- or data-parallel rendering and impose restrictions on the data distribution, requiring different implementations for each configuration. In this paper, we introduce the Distributed FrameBuffer, an asynchronous image-processing framework for multi-node rendering. We demonstrate that our approach achieves performance superior to the state of the art for common use cases, while providing the flexibility to support a wide range of parallel rendering algorithms and data distributions. By building on this framework, we extend the open-source ray tracing library OSPRay with a data-distributed API, enabling its use in data-distributed and in situ visualization applications.
2018
![]()
H. Bhatia, A.G. Gyulassy, V. Lordi, J.E. Pask, V. Pascucci, P.T. Bremer.
“TopoMS: Comprehensive topological exploration for molecular and condensed‐matter systems,” In Journal of Computational Chemistry, Vol. 39, No. 16, Wiley, pp. 936--952. March, 2018.
DOI: 10.1002/jcc.25181
We introduce TopoMS, a computational tool enabling detailed topological analysis of molecular and condensed‐matter systems, including the computation of atomic volumes and charges through the quantum theory of atoms in molecules, as well as the complete molecular graph. With roots in techniques from computational topology, and using a shared‐memory parallel approach, TopoMS provides scalable, numerically robust, and topologically consistent analysis. TopoMS can be used as a command‐line tool or with a GUI (graphical user interface), where the latter also enables an interactive exploration of the molecular graph. This paper presents algorithmic details of TopoMS and compares it with state‐of‐the‐art tools: Bader charge analysis v1.0 (Arnaldsson et al., 01/11/17) and molecular graph extraction using Critic2 (Otero‐de‐la‐Roza et al., Comput. Phys. Commun. 2014, 185, 1007). TopoMS not only combines the functionality of these individual codes but also demonstrates up to 4× performance gain on a standard laptop, faster convergence to fine‐grid solution, robustness against lattice bias, and topological consistency. TopoMS is released publicly under BSD License. © 2018 Wiley Periodicals, Inc.
![]()
S. Kumar, A. Humphrey, W. Usher, S. Petruzza, B. Peterson, J. A. Schmidt, D. Harris, B. Isaac, J. Thornock, T. Harman, V. Pascucci,, M. Berzins.
“Scalable Data Management of the Uintah Simulation Framework for Next-Generation Engineering Problems with Radiation,” In Supercomputing Frontiers, Springer International Publishing, pp. 219--240. 2018.
ISBN: 978-3-319-69953-0
DOI: 10.1007/978-3-319-69953-0_13
The need to scale next-generation industrial engineering problems to the largest computational platforms presents unique challenges. This paper focuses on data management related problems faced by the Uintah simulation framework at a production scale of 260K processes. Uintah provides a highly scalable asynchronous many-task runtime system, which in this work is used for the modeling of a 1000 megawatt electric (MWe) ultra-supercritical (USC) coal boiler. At 260K processes, we faced both parallel I/O and visualization related challenges, e.g., the default file-per-process I/O approach of Uintah did not scale on Mira. In this paper we present a simple to implement, restructuring based parallel I/O technique. We impose a restructuring step that alters the distribution of data among processes. The goal is to distribute the dataset such that each process holds a larger chunk of data, which is then written to a file independently. This approach finds a middle ground between two of the most common parallel I/O schemes--file per process I/O and shared file I/O--in terms of both the total number of generated files, and the extent of communication involved during the data aggregation phase. To address scalability issues when visualizing the simulation data, we developed a lightweight renderer using OSPRay, which allows scientists to visualize the data interactively at high quality and make production movies. Finally, this work presents a highly efficient and scalable radiation model based on the sweeping method, which significantly outperforms previous approaches in Uintah, like discrete ordinates. The integrated approach allowed the USC boiler problem to run on 260K CPU cores on Mira.
![]()
S. Liu, P.T. Bremer, J.J. Thiagarajan, V. Srikumar, B. Wang, Y. Livnat, V. Pascucci.
“Visual Exploration of Semantic Relationships in Neural Word Embeddings,” In IEEE Transactions on Visualization and Computer Graphics, Vol. 24, No. 1, IEEE, pp. 553--562. Jan, 2018.
DOI: 10.1109/tvcg.2017.2745141
Constructing distributed representations for words through neural language models and using the resulting vector spaces for analysis has become a crucial component of natural language processing (NLP). However, despite their widespread application, little is known about the structure and properties of these spaces. To gain insights into the relationship between words, the NLP community has begun to adapt high-dimensional visualization techniques. In particular, researchers commonly use t-distributed stochastic neighbor embeddings (t-SNE) and principal component analysis (PCA) to create two-dimensional embeddings for assessing the overall structure and exploring linear relationships (e.g., word analogies), respectively. Unfortunately, these techniques often produce mediocre or even misleading results and cannot address domain-specific visualization challenges that are crucial for understanding semantic relationships in word embeddings. Here, we introduce new embedding techniques for visualizing semantic and syntactic analogies, and the corresponding tests to determine whether the resulting views capture salient structures. Additionally, we introduce two novel views for a comprehensive study of analogy relationships. Finally, we augment t-SNE embeddings to convey uncertainty information in order to allow a reliable interpretation. Combined, the different views address a number of domain-specific tasks difficult to solve with existing tools.
![]()
S. Petruzza, A. Gyulassy, V. Pascucci,, P. T. Bremer.
“A Task-Based Abstraction Layer for User Productivity and Performance Portability in Post-Moore’s Era Supercomputing,” In 3RD INTERNATIONAL WORKSHOP ON POST-MOORE’S ERA SUPERCOMPUTING (PMES), 2018.
The proliferation of heterogeneous computing architectures in current and future supercomputing systems dramatically increases the complexity of software development and exacerbates the divergence of software stacks. Currently, task-based runtimes attempt to alleviate these impediments, however their effective use requires expertise and deep integration that does not facilitate reuse and portability. We propose to introduce a task-based abstraction layer that separates the definition of the algorithm from the runtime-specific implementation, while maintaining performance portability.
![]()
S. Petruzza, A. Gyulassy, V. Pascucci,, P. T. Bremer.
“A Task-Based Abstraction Layer for User Productivity and Performance Portability in Post-Moore’s Era Supercomputing,” In 3RD INTERNATIONAL WORKSHOP ON POST-MOORE’S ERA SUPERCOMPUTING (PMES), 2018.
The proliferation of heterogeneous computing architectures in current and future supercomputing systems dramatically increases the complexity of software development and exacerbates the divergence of software stacks. Currently, task-based runtimes attempt to alleviate these impediments, however their effective use requires expertise and deep integration that does not facilitate reuse and portability. We propose to introduce a task-based abstraction layer that separates the definition of the algorithm from the runtime-specific implementation, while maintaining performance portability.
![]()
B. Summa, N. Faraj, C. Licorish, V. Pascucci.
“Flexible Live‐Wire: Image Segmentation with Floating Anchors,” In Computer Graphics Forum, Vol. 37, No. 2, Wiley, pp. 321-328. May, 2018.
DOI: 10.1111/cgf.13364
We introduce Flexible Live‐Wire, a generalization of the Live‐Wire interactive segmentation technique with floating anchors. In our approach, the user input for Live‐Wire is no longer limited to the setting of pixel‐level anchor nodes, but can use more general anchor sets. These sets can be of any dimension, size, or connectedness. The generality of the approach allows the design of a number of user interactions while providing the same functionality as the traditional Live‐Wire. In particular, we experiment with this new flexibility by designing four novel Live‐Wire interactions based on specific primitives: paint, pinch, probable, and pick anchors. These interactions are only a subset of the possibilities enabled by our generalization. Moreover, we discuss the computational aspects of this approach and provide practical solutions to alleviate any additional overhead. Finally, we illustrate our approach and new interactions through several example segmentations.
![]()
W Usher, P Klacansky, F Federer, PT Bremer, A Knoll, J. Yarch, A. Angelucci, V. Pascucci .
“A virtual reality visualization tool for neuron tracing,” In IEEE Transactions on Visualization and Computer Graphics, Vol. 24, No. 1, IEEE, pp. 994--1003. Jan, 2018.
DOI: 10.1109/tvcg.2017.2744079
racing neurons in large-scale microscopy data is crucial to establishing a wiring diagram of the brain, which is needed to understand how neural circuits in the brain process information and generate behavior. Automatic techniques often fail for large and complex datasets, and connectomics researchers may spend weeks or months manually tracing neurons using 2D image stacks. We present a design study of a new virtual reality (VR) system, developed in collaboration with trained neuroanatomists, to trace neurons in microscope scans of the visual cortex of primates. We hypothesize that using consumer-grade VR technology to interact with neurons directly in 3D will help neuroscientists better resolve complex cases and enable them to trace neurons faster and with less physical and mental strain. We discuss both the design process and technical challenges in developing an interactive system to navigate and manipulate terabyte-sized image volumes in VR. Using a number of different datasets, we demonstrate that, compared to widely used commercial software, consumer-grade VR presents a promising alternative for scientists.
![]()
W. Usher, S. Rizzi, I. Wald, J. Amstutz, J. Insley, V. Vishwanath, N. Ferrier, M. E. Papka,, V. Pascucci.
“libIS: A Lightweight Library for Flexible In Transit Visualization,” In Proceedings of the Workshop on In Situ Infrastructures for Enabling Extreme-Scale Analysis and Visualization, ACM Press, 2018.
DOI: 10.1145/3281464.3281466
As simulations grow in scale, the need for in situ analysis methods to handle the large data produced grows correspondingly. One desirable approach to in situ visualization is in transit visualization. By decoupling the simulation and visualization code, in transit approaches alleviate common difficulties with regard to the scalability of the analysis, ease of integration, usability, and impact on the simulation. We present libIS, a lightweight, flexible library which lowers the bar for using in transit visualization. Our library works on the concept of abstract regions of space containing data, which are transferred from the simulation to the visualization clients upon request, using a client-server model. We also provide a SENSEI analysis adaptor, which allows for transparent deployment of in transit visualization. We demonstrate the flexibility of our approach on batch analysis and interactive visualization use cases on different HPC resources.
2017
![]()
S. Kumar, D. Hoang, S. Petruzza, J. Edwards, V. Pascucci.
“Reducing Network Congestion and Synchronization Overhead During Aggregation of Hierarchical Data,” In 2017 IEEE 24th International Conference on High Performance Computing (HiPC), pp. 223-232. Dec, 2017.
DOI: 10.1109/HiPC.2017.00034
Hierarchical data representations have been shown to be effective tools for coping with large-scale scientific data. Writing hierarchical data on supercomputers, however, is challenging as it often involves all-to-one communication during aggregation of low-resolution data which tends to span the entire network domain, resulting in several bottlenecks. We introduce the concept of indexing templates, which succinctly describe data organization and can be used to alter movement of data in beneficial ways. We present two techniques, domain partitioning and localized aggregation, that leverage indexing templates to alleviate congestion and synchronization overheads during data aggregation. We report experimental results that show significant I/O speedup using our proposed schemes on two of today's fastest supercomputers, Mira and Shaheen II, using the Uintah and S3D simulation frameworks.
![]()
S. Kumar, D. Hoang, S. Petruzza, J. Edwards, V. Pascucci.
“Reducing network congestion and synchronization overhead during aggregation of hierarchical data,” In 2017 IEEE 24th International Conference on High Performance Computing (HiPC), IEEE, Dec, 2017.
DOI: 10.1109/hipc.2017.00034
Hierarchical data representations have been shown to be effective tools for coping with large-scale scientific data. Writing hierarchical data on supercomputers, however, is challenging as it often involves all-to-one communication during aggregation of low-resolution data which tends to span the entire network domain, resulting in several bottlenecks. We introduce the concept of indexing templates, which succinctly describe data organization and can be used to alter movement of data in beneficial ways. We present two techniques, domain partitioning and localized aggregation, that leverage indexing templates to alleviate congestion and synchronization overheads during data aggregation. We report experimental results that show significant I/O speedup using our proposed schemes on two of today's fastest supercomputers, Mira and Shaheen II, using the Uintah and S3D simulation frameworks.
![]()
S. Petruzza, A. Venkat, A. Gyulassy, G. Scorzelli, F. Federer, A. Angelucci, V. Pascucci, P. T. Bremer.
“ISAVS: Interactive Scalable Analysis and Visualization System,” In ACM SIGGRAPH Asia 2017 Symposium on Visualization, ACM Press, 2017.
DOI: 10.1145/3139295.3139299
Modern science is inundated with ever increasing data sizes as computational capabilities and image acquisition techniques continue to improve. For example, simulations are tackling ever larger domains with higher fidelity, and high-throughput microscopy techniques generate larger data that are fundamental to gather biologically and medically relevant insights. As the image sizes exceed memory, and even sometimes local disk space, each step in a scientific workflow is impacted. Current software solutions enable data exploration with limited interactivity for visualization and analytic tasks. Furthermore analysis on HPC systems often require complex hand-written parallel implementations of algorithms that suffer from poor portability and maintainability. We present a software infrastructure that simplifies end-to-end visualization and analysis of massive data. First, a hierarchical streaming data access layer enables interactive exploration of remote data, with fast data fetching to test analytics on subsets of the data. Second, a library simplifies the process of developing new analytics algorithms, allowing users to rapidly prototype new approaches and deploy them in an HPC setting. Third, a scalable runtime system automates mapping analysis algorithms to whatever computational hardware is available, reducing the complexity of developing scaling algorithms. We demonstrate the usability and performance of our system using a use case from neuroscience: filtering, registration, and visualization of tera-scale microscopy data. We evaluate the performance of our system using a leadership-class supercomputer, Shaheen II.
![]()
W. Usher, P. Klacansky, F. Federer, P. T. Bremer, A. Knoll, J. Yarch, A. Angelucci, V. Pascucci.
“A Virtual Reality Visualization Tool for Neuron Tracing,” In IEEE Transactions on Visualization and Computer Graphics, IEEE, 2017.
ISSN: 1077-2626
DOI: 10.1109/TVCG.2017.2744079
Tracing neurons in large-scale microscopy data is crucial to establishing a wiring diagram of the brain, which is needed to understand how neural circuits in the brain process information and generate behavior. Automatic techniques often fail for large and complex datasets, and connectomics researchers may spend weeks or months manually tracing neurons using 2D image stacks. We present a design study of a new virtual reality (VR) system, developed in collaboration with trained neuroanatomists, to trace neurons in microscope scans of the visual cortex of primates. We hypothesize that using consumer-grade VR technology to interact with neurons directly in 3D will help neuroscientists better resolve complex cases and enable them to trace neurons faster and with less physical and mental strain. We discuss both the design process and technical challenges in developing an interactive system to navigate and manipulate terabyte-sized image volumes in VR. Using a number of different datasets, we demonstrate that, compared to widely used commercial software, consumer-grade VR presents a promising alternative for scientists.
2016
![]()
C. Christensen, S. Liu, G. Scorzelli, J. Lee, P.-T. Bremer, V. Pascucci.
“Embedded Domain-Specific Language and Runtime System for Progressive Spatiotemporal Data Analysis and Visualization,” In Symposium on Large Data Analysis and Visualization, IEEE, 2016.
As our ability to generate large and complex datasets grows, accessing and processing these massive data collections is increasingly the primary bottleneck in scientific analysis. Challenges include retrieving, converting, resampling, and combining remote and often disparately located data ensembles with only limited support from existing tools. In particular, existing solutions rely predominantly on extensive data transfers or large-scale remote computing resources, both of which are inherently offline processes with long delays and substantial repercussions for any mistakes. Such workflows severely limit the flexible exploration and rapid evaluation of new hypotheses that are crucial to the scientific process and thereby impede scientific discovery. Here we present an embedded domain-specific language (EDSL) specifically designed for the interactive exploration of largescale, remote data. Our EDSL allows users to express a wide range of data analysis operations in a simple and abstract manner. The underlying runtime system transparently resolves issues such as remote data access and resampling while at the same time maintaining interactivity through progressive and interruptible computation. This system enables, for the first time, interactive remote exploration of massive datasets such as the 7km NASA GEOS-5 Nature Run simulation, which previously have been analyzed only offline or at reduced resolution.
![]()
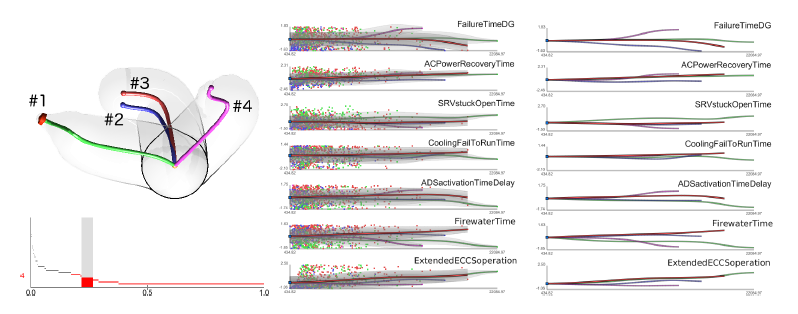
D. Maljovec, S. Liu, Bei Wang, V. Pascucci, P. T. Bremer, D. Mandelli, C. Smith..
“Analyzing Simulation-Based PRA Data Through Traditional and Topological Clustering: A BWR Station Blackout Case Study,” In Reliability Engineering & System Safety, Vol. 145, Elsevier, pp. 262--276. January, 2016.
DOI: 10.1016/j.ress.2015.07.001
![]()
I. Rodero, M. Parashar, A.G. Landge, S. Kumar, V. Pascucci,, P.T. Bremer.
“Evaluation of in-situ analysis strategies at scale for power efficiency and scalability,” In Cluster, Cloud and Grid Computing (CCGrid), 2016 16th IEEE/ACM International Symposium on, IEEE, pp. 156--164. 2016.
The increasing gap between available compute power and I/O capabilities is resulting in simulation pipelines running on leadership computing facilities being reformulated. In particular, in-situ processing is complementing conventional post-process analysis; however, it can be performed by using the same compute resources as the simulation or using secondary dedicated resources.
In this paper, we focus on three different in-situ analysis strategies, which use the same compute resources as the ongoing simulation but different data movement strategies. We evaluate the costs incurred by these strategies in terms of run time, scalability and power/energy consumption. Furthermore, we extrapolate power behavior to peta-scale and investigate different design choices through projections. Experimental evaluation at full machine scale on Titan supports that using fewer cores per node for in-situ analysis is the optimum choice in terms of scalability. Hence, further research effort should be devoted towards developing in-situ analysis techniques following this strategy in future high-end systems.
Page 3 of 13