Semi-Supervised Learning
Training high accuracy classifiers often requires a very large amount of labeled training data. Recently, ConvNets have shown impressive results on many vision tasks including but not limited to classification, detection, localization and scene labeling. However, ConvNets work best when a large amount of labeled data is available for supervised training. For example, the state-of-the-art results for large 1000-category ’ImageNet’ dataset was significantly improved using ConvNets. Unfortunately, building large labeled datasets is a costly and time consuming process. On the other hand, unlabeled data is easy to obtain. Semi-supervised learning uses unlabeled data to train a model with higher accuracy when there is a limited set of labeled data available. The following example illustrates the effect of unlabeled data on decision function.
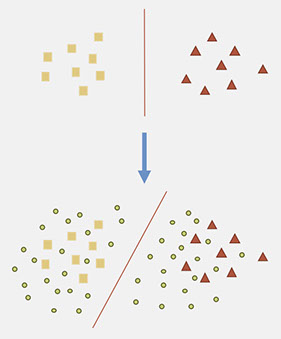
We propose two different unsupervised loss functions that complement each other. They can be used with any classifier which is based on gradient descent using back-propagation. We show using numerous experiments that our proposed loss functions improve the accuracy of ConvNets that are only trained using labeled data.
In this work we propose an unsupervised regularization term that explicitly forces the classifier’s prediction for multiple classes to be mutually-exclusive and effectively guides the decision boundary to lie on the low density space between the manifolds corresponding to different classes of data.
In this work, we propose an unsupervised loss function that takes advantage of the stochastic nature of techniques such as randomized data augmentation, dropout and random max-pooling and minimizes the difference between the predictions of multiple passes of a training sample through the network.
© 2014
Scientific Computing and Imaging Institute