Transformation/Stability Loss
Given any training sample, a model’s prediction should be the same under any random transformation of the data and perturbations to the model. The transformations can be any linear and non-linear data augmentation being used to extend the training data. The disturbances include dropout techniques and randomized pooling schemes. In each pass, each sample can be randomly transformed or the hidden nodes can be randomly activated. As a result, the network’s prediction can be different for multiple passes of the same training sample. However, we know that each sample is assigned to only one class. Therefore, the network’s prediction is expected to be the same despite transformations and disturbances. We introduce an unsupervised loss function that minimizes the mean squared differences between different passes of an individual training sample through the network. Note that we do not need to know the label of a training sample in order to enforce this loss. Therefore, the proposed loss function is completely unsupervised and can be used along with supervised training as a semi-supervised learning method. Here is the unsupervised loss function that we minimize:
$$ l_{\mathcal{U}}^\text{TS} = \sum_{j=1}^{n-1} \sum_{k=j+1}^n \| \mathbf{f}^j(T^j(\mathbf{x}_i)) - \mathbf{f}^k(T^k(\mathbf{x_i})) \|_2^2 $$
Here, \( \mathbf{f}^j(\mathbf{x}_i) \) is the classifier's prediction vector on the \( i \)'th training sample during the \( j \)'th pass through the network. We assume that each training sample is passed \( n \) times through the network. We define the \( T^j(\mathbf{x}_i) \) to be a random linear or non-linear transformation on the training sample \( \mathbf{x}_i \) before the \( j \)'th pass through the network.
We performed different experiments on numerous datasets using our proposed loss function. Details can be found in our paper. Here, we show examples on MNIST, NORB and SVHN. In the case of MNIST, we take advantage of the random effects of dropout and fractional max-pooling using the unsupervised loss function. We randomly select 10 samples from each class (total of 100 labeled samples). We use all available training data as the unlabeled set. First, we train a model based on this labeled set only. Then, we train models by adding unsupervised loss functions. In separate experiments, we add transformation/stability loss function, mutual-exclusivity loss function and the combination of both. Each experiment is repeated five times with a different random subset of training samples. We repeat the same set of experiments using 100% of MNIST training samples. The results are given in the following table:

For NORB and SVHN, we randomly choose 1%, 5%, 10%, 20% and 100% of training samples as labeled data. All of the training samples are used as the unlabeled set. For each labeled set, we train four models using cuda-convnet. The first model uses labeled set only. The second model is trained on unlabeled set using mutual-exclusivity loss function in addition to the labeled set. The third model is trained on the unlabeled set using the transformation/stability loss function in addition to the labeled set. The last model is also trained on both sets but combines two unsupervised loss functions. Each experiment is repeated five times. For each repetition, we use a different subset of training samples as labeled data. We use data augmentation for these experiments. The results are shown in the following figures:
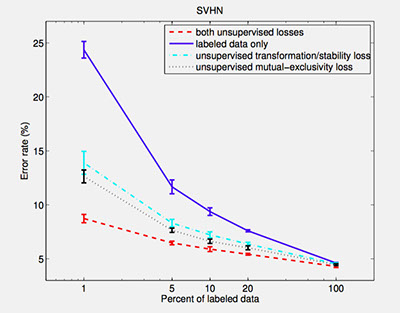
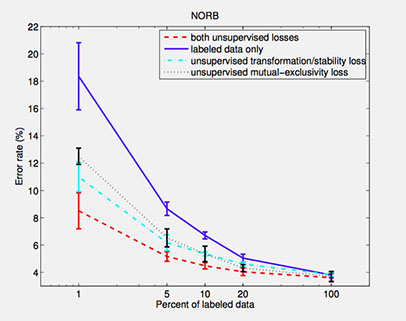
References:
[1] Mehdi Sajjadi, Mehran Javanmardi, and Tolga Tasdizen. "Regularization With Stochastic Transformations and Perturbations for Deep Semi-Supervised Learning." NIPS 2016.
[2] Rasmus, Antti, et al. "Semi-supervised learning with ladder networks." Advances in Neural Information Processing Systems. 2015.
[3] Dosovitskiy, Alexey, et al. "Discriminative unsupervised feature learning with convolutional neural networks." Advances in Neural Information Processing Systems. 2014.
© 2014
Scientific Computing and Imaging Institute