ShapeOdds for Grid-structured Shapes
Motivation: Shape models of grid-structured representations, a.k.a. label maps or silhouettes, provide a compact parameterization of a class of shapes, and have been shown to be a useful tool for a variety of medical imaging and vision tasks that use shapes to augment other sources of information to solve a specific inverse or forward problem, e.g., object detection, tracking, shape analysism and image segmentation. The premise here is that different instances of an object class attain clear differences in shape; however, they share typical characteristics that stem from the underlying mechanisms involved in their formation. This premise motivates learning variability patterns of a shape population via modeling it probability distribution from a set of i.i.d. training samples - treated as data points in a high-dimensional shape space - drawn from an unknown distribution.
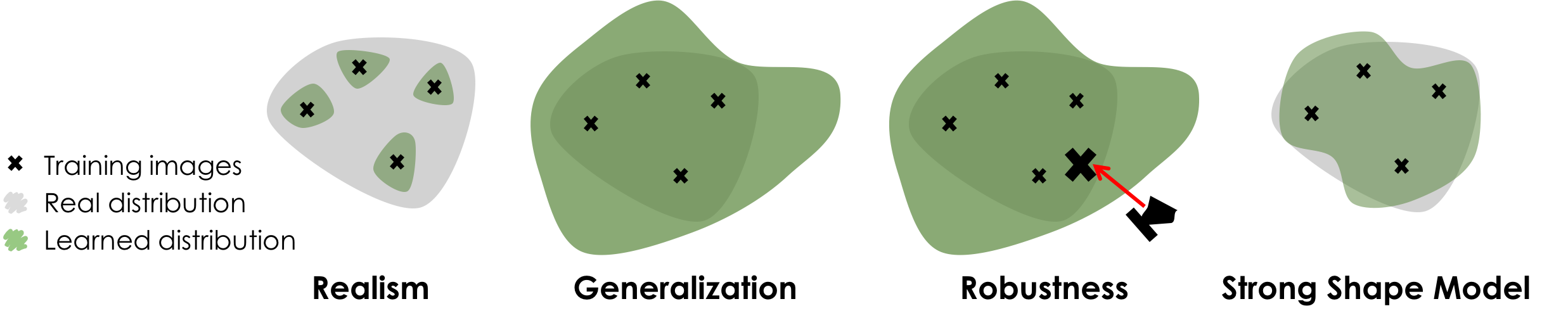
A strong shape model should balance the trade off between three requirements, namely realism, generalization and robustness. In particular, a shape model needs to generate samples that look realistic, it also needs to generate samples that go beyond the training data while being able to handle unbiased noise (i.e., missing regions and/or background clutter).
However, learning such models in the native space of label maps (or silhouettes) is challenging. The binary variables entail non-Gaussian data likelihood, which leads to intractable marginals and posteriors. The combination of high-dimensional shape space and limited training samples presents a risk of overfitting. The hyperparameters associated with model complexity often result in computationally expensive discrete searches. Furthermore, nonlinear shape variation is often rendered as multimodal probability distributions, which confound the many approaches that rely on Gaussian assumptions.
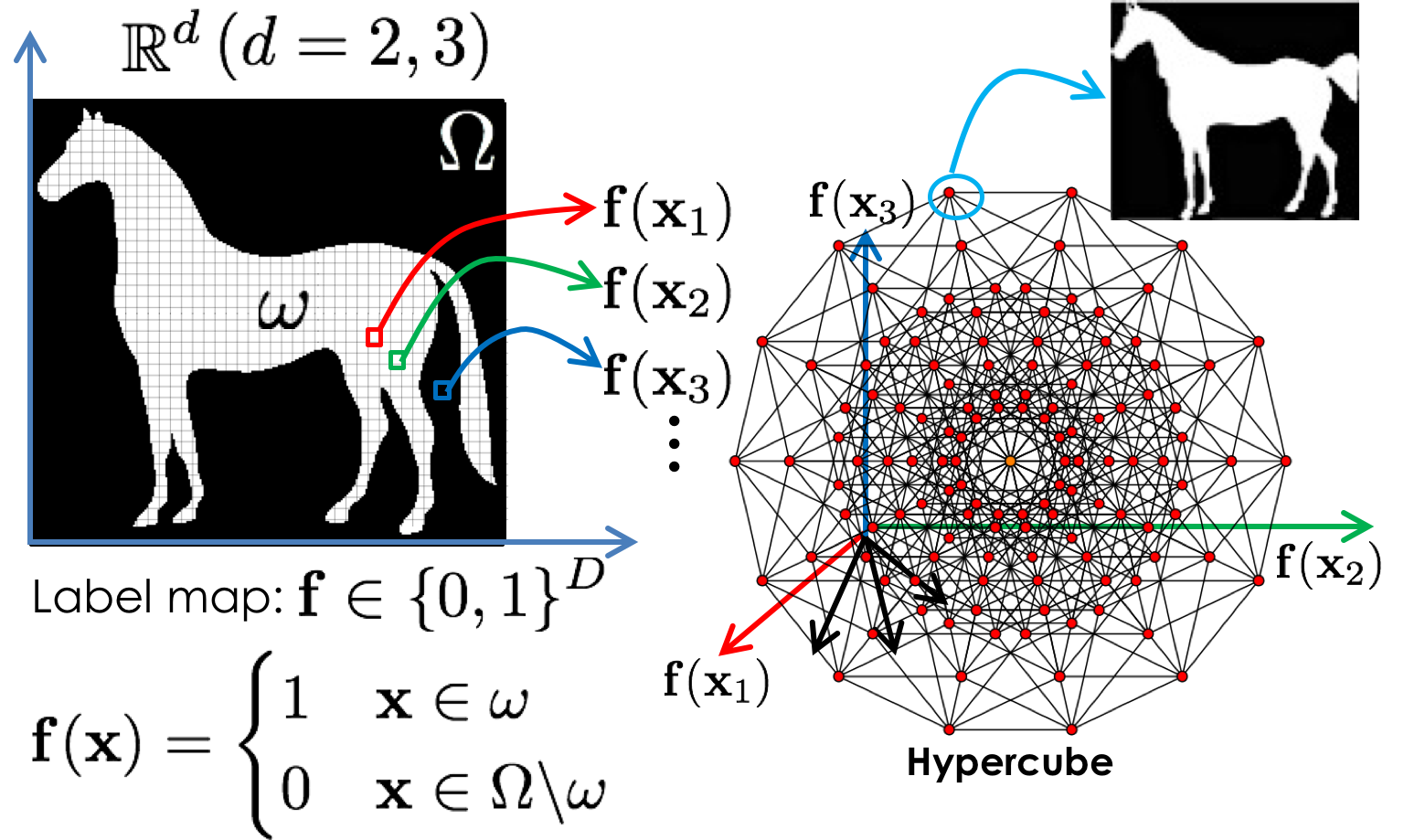
A label map \(\mathbf{f}\) defines a labeling function that maps each image pixel \(\mathbf{x}\) in \(\mathbb{R}^d\) to a single label from a set of labels. Here we will focus on a single object scenario where we only have foreground and background (i.e. two labels). In the label maps space, each pixel defines a coordinate and since each pixel can only attain a one or zero value, the space of these label maps is a hypercube where each corner correspond to a different label map.
- Optimal probabilistic shape representation
- ShapeOdds: variational Bayesian learning of generative shape models
- Mixture of ShapeOdds for modeling multimodal probability distributions
- Infinite ShapeOdds for modeling nonlinear probability distributions
Optimal probabilistic shape representation
Joint work with: Ross Whitaker
This research has a natural tiered structure where we started by introducing a data-driven approach for defining a probabilistic representation of shape, known as a relaxed notion of shape to learn shape priors with convexity merits of the resulting optimization schemes. This probabilistic representation encodes uncertainties associated with a pixel-wise label assignment which reflects the likeliness of assigning a pixel to the object-of-interest. Thus, such a representation can be considered as a parametric distribution over the label maps space. Existing methods define this parametric distribution through heuristics that do not typically have a statistical foundation, leading to suboptimal generative models. For example, commonly used representations include sigmoid of signed distance maps (SDMs); where distance of a voxel to the shape’s boundary does not correlate well with the underlying probability distribution over label maps. Another popular representation is smoothed average of label maps. However blurring of label maps blindly smooths out shape features irrespective of the degree of uncertainty along shape boundary.
In this regard, the proposed data-driven approach seeks to learn an optimal probability distribution over the label maps space that is consistent with the inherent generative model of a shape population. The proposed formulation relies on an unconstrained optimization in the natural parameter space of the exponential family form of Bernoulli distributions. To alleviate overfitting in this high-dimensional-low-sample-size scenario, we introduced a smoothness prior on the natural parameter map to impose spatial regularity of the estimated parameters. Proposed approach performed better as compared to existing practices such as blurred signed distance maps, smoothed average of label maps and optimized weighted average of label maps. We further demonstrated the performance of the proposed approach on consensus generation, shape clustering, and shape-based segmentation.
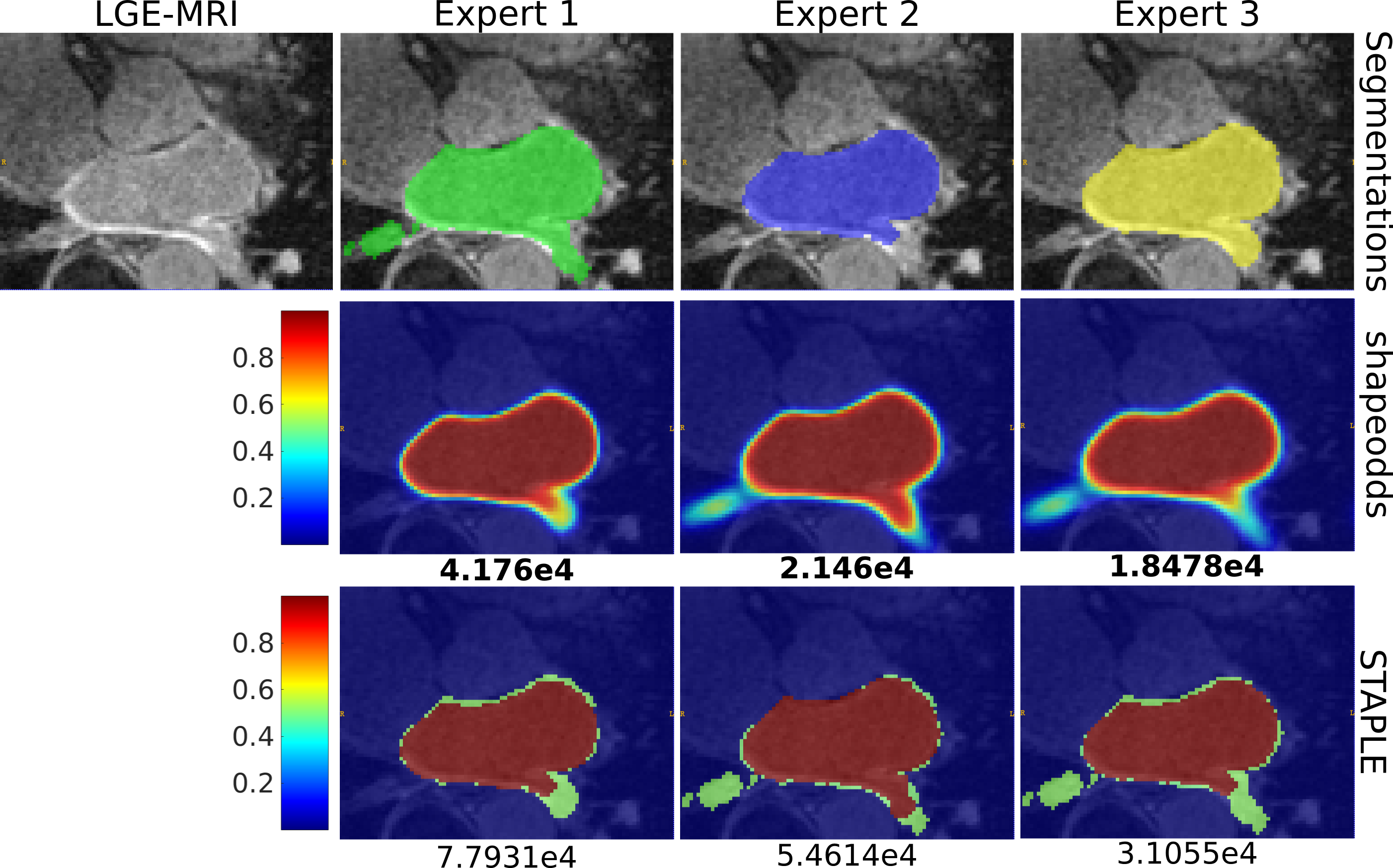
Consensus of the epicardium of sample LGE-MRI slice. The first row shows the manual segmentations of three human experts who disagree on the accurate contour of epicardium. The second and third rows show the parameter maps estimated via ShapeOdds and STAPLE, respectively, by leaving the respective expert segmentation out of the training sample. Negative log-likelihood of the expert segmentation given the ShapeOdds/STAPLE parameter map is also reported.
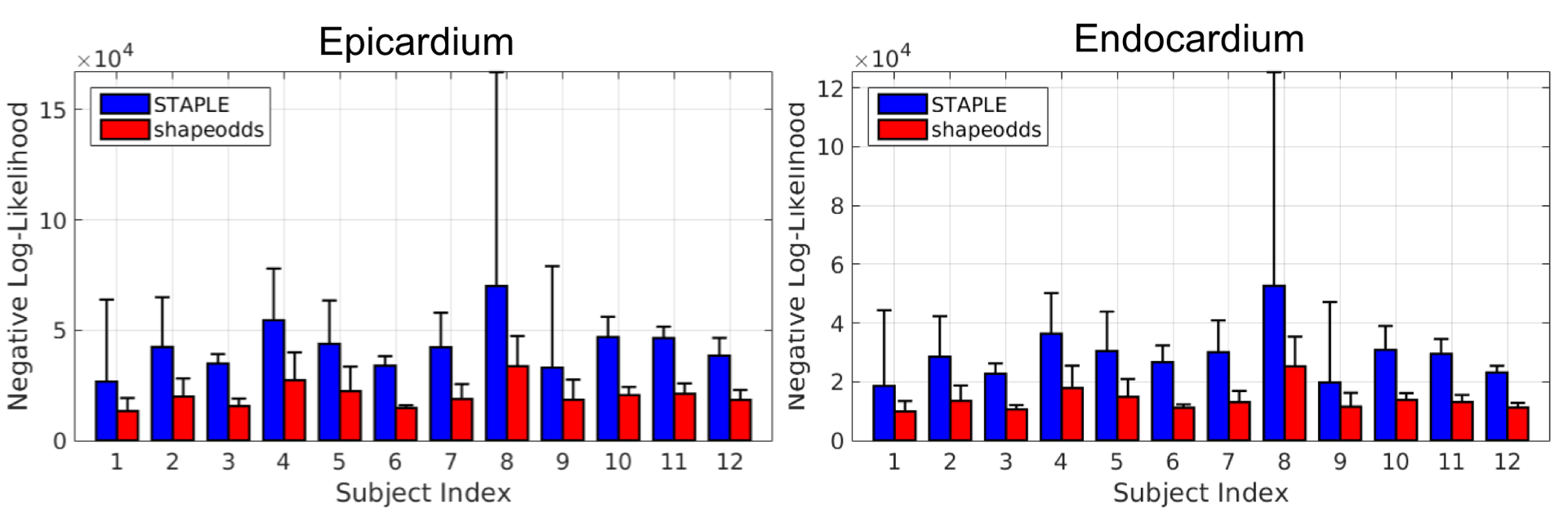
Consensus generation: The average and standard deviation of negative log-likelihood (lower is better) of held-out manual segmentations for epicardium (left) and endocardium (right) using the proposed and STAPLE parameters maps. Notice that the proposed optimal parameter maps is able to generalize to unseen samples compared to those of STAPLE.
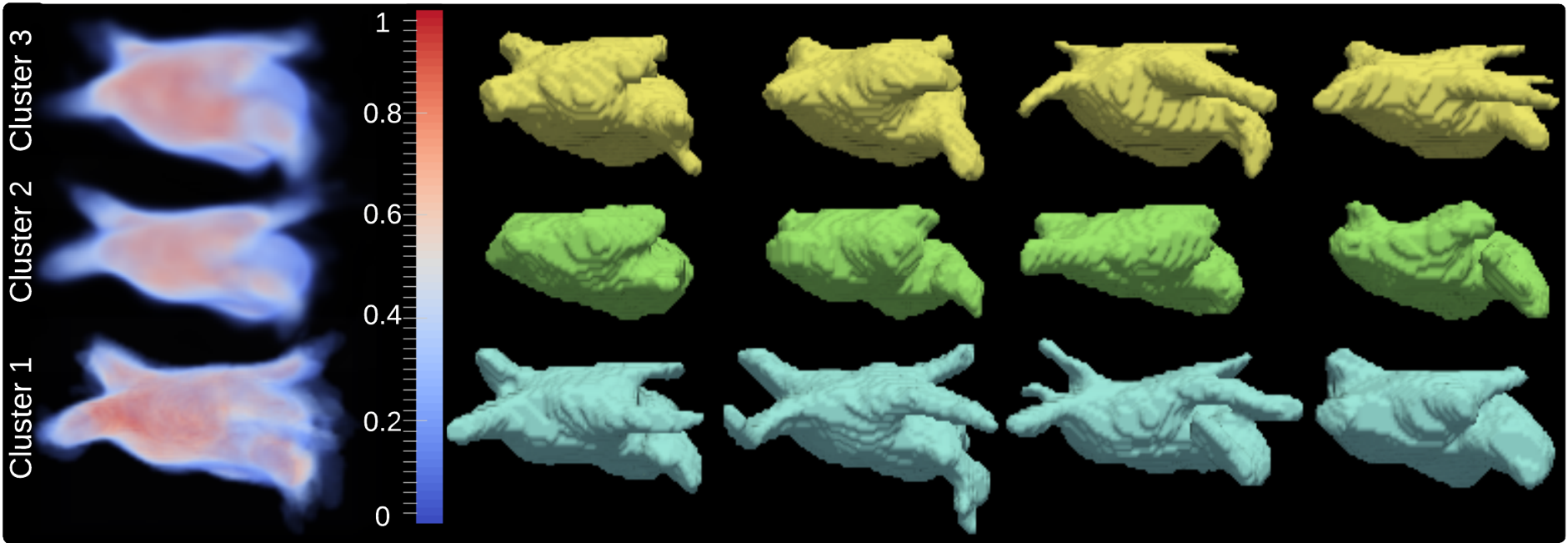
Estimated parameters maps and samples from final clusters of left atrium shapes trained using 62 left atriums manually segmented from LGE-MRI from patients with atrial fibrillation. Samples for each cluster are presented in decreasing order of log-likelihood (left to right).

Clustering results with real 3D silhouettes of Human Actions. Samples for each cluster are presented in decreasing order of log-likelihood (top to bottom). It can be observed that ShapeOdds-based clustering has obtained semantically meaningful partitions corresponding to known human actions.

Samples of Caltech leaves segmentations using (middle) nonparametric shape prior and (right) multiple ShapeOdds parameter maps. Dice coefficients are also reported. It can be observed that non-parameteric shape priors, being represented via SDMs, resulted in sub-optimal segmentation performance as compared to our generative shape prior. Further, nonparametric kernel density estimation poses an optimization challenge in high dimensional spaces.

Sample occluded leaves with artificial occluding objects and the corresponding segmentation results obtained using single and multiple parameter maps. (a) occluded leave, (b) segmentation result using a single parameter map shown in (c), and (d) segmentation result using multiple parameter map where the algorithm converges to the parameter map shown in (e). Notice that the appearance model of the object is significantly affected under occlusion. This emphasizes the importance of multimodal shape prior in the presence of misleading image information.
Recently, we extended this formulation in a significant way to the multi-category scenario to estimate optimal probabilistic label maps for anatomical ensembles with an arbitrary number of labels. We propose to estimate probabilistic labeling for a set of multi-label maps based on a generative model, constructed over the field of categorical, a.k.a. multinoulli, random variables defined over the spatial domain. The optimal probabilistic segmentation is estimated as a maximum-a-posteriori (MAP) estimate of the corresponding natural parameters of the exponential family form of multinoulli distributions.
With the experimental results, we showcased that the proposed method can be used for various medical imaging applications. The representation obtained by the proposed method outperformed the current ad hoc practice of averaging the smoothed label maps for medical image segmentation, multi-atlas segmentation, and consensus generation (for two labels case). Specifically, the importance of the proposed method is highlighted by robust results obtained with a small number of training samples for all three datasets used for the experiments. Further, effective shape-based clustering can be performed using the representation obtained from the proposed method.
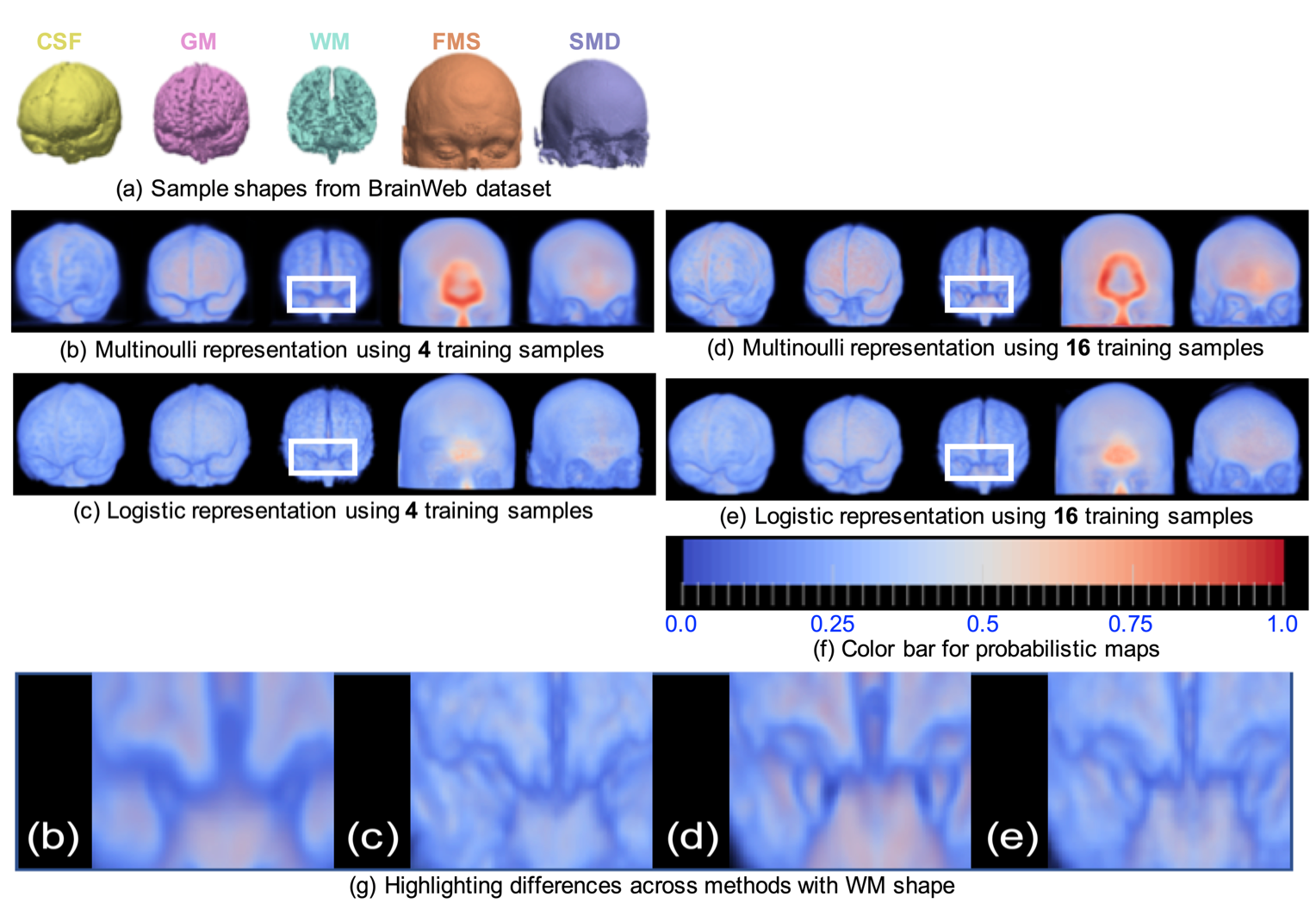
(a) A sample of five foreground labels in the BrainWeb dataset, (b) Multinoulli representation obtained using four training samples, (c) Logistic representation obtained using four training samples, (d) Multi- noulli representation obtained using 16 training samples, (e) Logistic representation obtained using 16 training samples, (f) color map for the shape representations and (g) comparing the zoomed snapshot from the four representations in (b)–(e) for WM (white matter) shape.
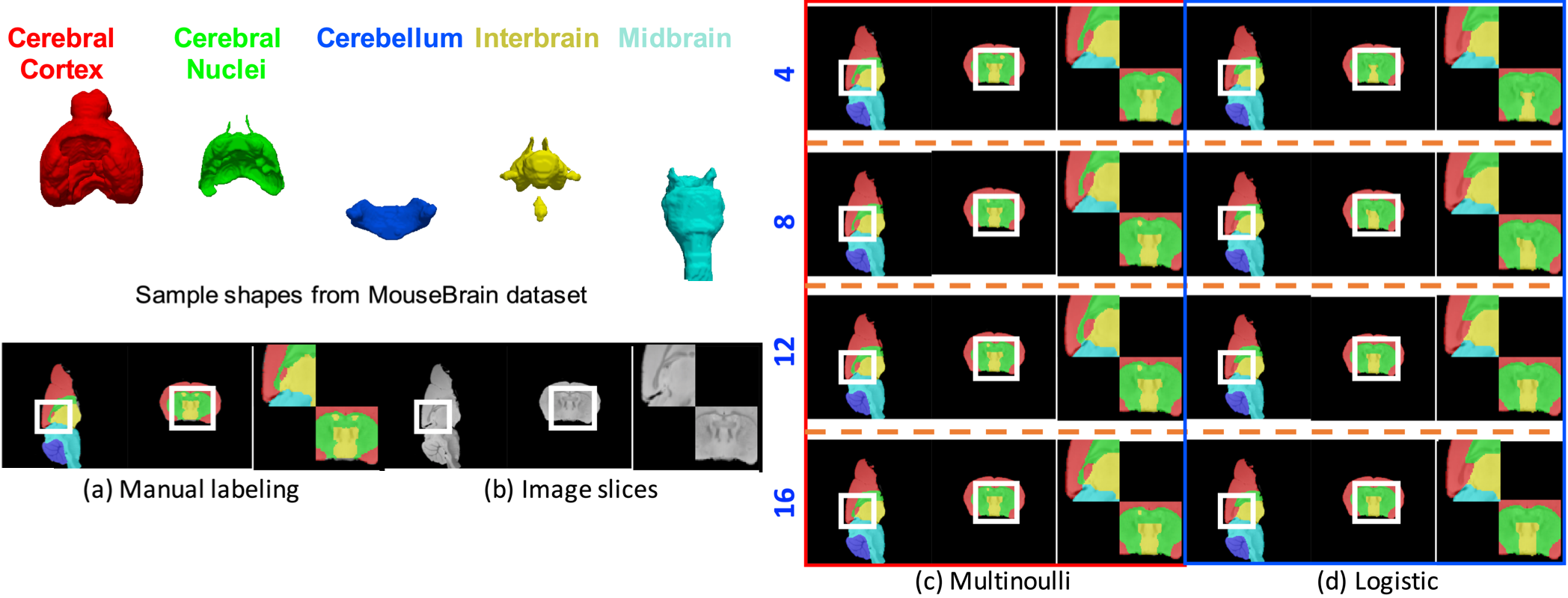
(a) Sample slices of manual segmentations and zoomed rectangular regions from the MouseBrain dataset, (b) Image slices corresponding to segmentations in (a) and zoomed rectangular regions. Results obtained using (c) Multinoulli representation and (d) Logistic representation, with different training sample sizes. All results and zoomed figures correspond to the segmentations and image slices presented in (a) and (b), respectively.
Related publications:
Shireen Y. Elhabian, Praful Agrawal, Ross Whitaker. Optimal Parameter Map Estimation for Shape Representation: A Generative Approach. In IEEE 13th International Symposium of Biomedical Imaging (ISBI), 2016.
Praful Agrawal, Ross Whitaker, Shireen Y. Elhabian. An Optimal, Generative Model for Estimating Multi-label Probabilistic Maps. IEEE Transaction of Medical Imaging, in press, 2020.
ShapeOdds: variational Bayesian learning of generative shape models
Joint work with: Ross Whitaker
There is a rich history of work on learning shape statistics from label maps (or silhouettes). The main distinction is capturing local (i.e. low-level) versus global (i.e high-level) correlations. Local structure interactions between pixels typically capture generic properties, e.g. smoothness and continuity (often via Markov random fields - MRFs). Here we focus on global models designed to capture complex high-level shape structure (e.g. facial parts, horse legs, vehicle wheels), which may also be complemented by low-level spatial priors.
Learning a probability distribution over the label maps space amounts to estimating the corresponding parameter map of a label map. Because the shape space is a unit hypercube, such a learning task does not benefit from a vector space structure. Consequently, most existing approaches have resorted to modeling shape variability indirectly on a space of some predefined implicit function, including signed distance maps (SDMs) and Gaussian smoothed silhouettes. However, such representations typically do not have a statistical foundation, and therefore do not benefit from optimal estimation strategies.
We proposed a Bayesian treatment of a latent variable model for learning generative shape models, called ShapeOdds, that relies on direct probabilistic formulation with a variational approach for deterministic model learning. Spatial coherency and sparsity priors were also incorporated to lend stability to the optimization problem, thereby regularizing the solution space while avoiding overfitting in this high-dimensional, low-sample-size scenario. A type-II maximum likelihood estimate of the model hyperparameters was deployed to avoid grid searches. Experiments showed the proposed model generates realistic samples, generalizes to unseen examples, and is able to handle missing regions and/or background clutter while comparing favorably with recent, neural-network-based approaches.

ShapeOdds: shape generating process.

Realism – sampled shapes from horses datasets using ShapeOdds and other baseline models. ShapeOdds can generate crisp parameter maps with significant shape variability while preserving shape details such as horse legs.

Generalization: (a) unseen silhouette, (b) closest silhouette in the training dataset, (c) overlay of (a) and (b) (red pixels are present only in the unseen sample, green pixels are present only in the training sample, and yellow pixels are present in both), reconstructed q maps from (d) ShapeOdds, (e) ShapeBM, (f) PCA-LogOdds-SDMs, (g) PCA-Prob-SDMs, (h) PCA-LogOdds-GAUSS, (i) PCA-Prob-GAUSS, and (j) KDE-SDMs. Generarlization measure G(u; q) (lower is better) is reported where bold indicates best generalization. ShapeOdds compares favorably against all baseline models and shows better generalization performance even with small training sizes compared to the underlying variability.
Inference contexts, e.g. segmentation and tracking, involve querying the learned shape model to infer the parameter map of the closest label map to a given corrupted one. Missing foreground regions and/or background clutter are rendered as a lack of compliance with the learned model, i.e. outliers, introducing an erroneous maximum likelihood estimate of the approximate posterior due to assigning higher weights to outlying pixels during the inference process. To increase the robustness of the estimated posterior, we deploy a functional, rho-functions in the robust statistics field, of the marginal bound that is more forgiving of outlying pixels. We formulated the inference problem in an optimization context without relying on explicitly detecting the outliers’ spatial support to be discarded from the inference process.

Robustness: (a) corrupted silhouette, (b) groundtruth silhouette, q maps recovered from (c) ShapeOdds-Robust, (d) ShapeOdds, (e) ShapeBM, (f) PCA-LogOdds-SDMs, (g) PCA-Prob-SDMs, (h) PCA-LogOdds-GAUSS, (i) PCA-Prob-GAUSS, and (j) KDE-SDMs. Cross entropy (lower is better) is reported where bold indicates best performance. ShapeOdds shows some success in handling low noise levels, but it fails to properly recover valid parameter maps for highly contaminated silhouettes. The proposed robust inference, on the other hand, maintains good performance even with high levels of foreground and/or background corruption.
Related publications:
Shireen Y. Elhabian and Ross T. Whitaker. ShapeOdds: Variational Bayesian Learning of Generative Shape Models. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2231-2242, 2017.
Mixture of ShapeOdds for modeling multimodal probability distributions
Joint work with: Ross Whitaker
Nonlinear shape variation is often rendered as multimodal probability distributions, which confound the many approaches that rely on Gaussian assumptions. To capture nonlinearities or subpopulations, the shape distribution can be approximated using a finite mixture of Gaussians in which model estimation is often made tractable by working with a low-dimensional projection of the data. Nonetheless, this global projection often collapses or mixes the subpopulations, which derails learning the mixture structure of the underlying shape space. Nonlinearity of shape statistics can also be modeled by lifting training shapes to a higher dimensional feature (aka kernel) space, where the shape distribution is often assumed to be Gaussian. However, one is faced with finding the reverse mapping from feature space to shape space (aka preimage problem), which is often solved approximately. In this regard, we proposed a mixture of ShapeOdds that learns complex shape distributions directly in the high-dimensional shape space without resorting to a global projection of training samples onto a low-dimensional linear subspace.
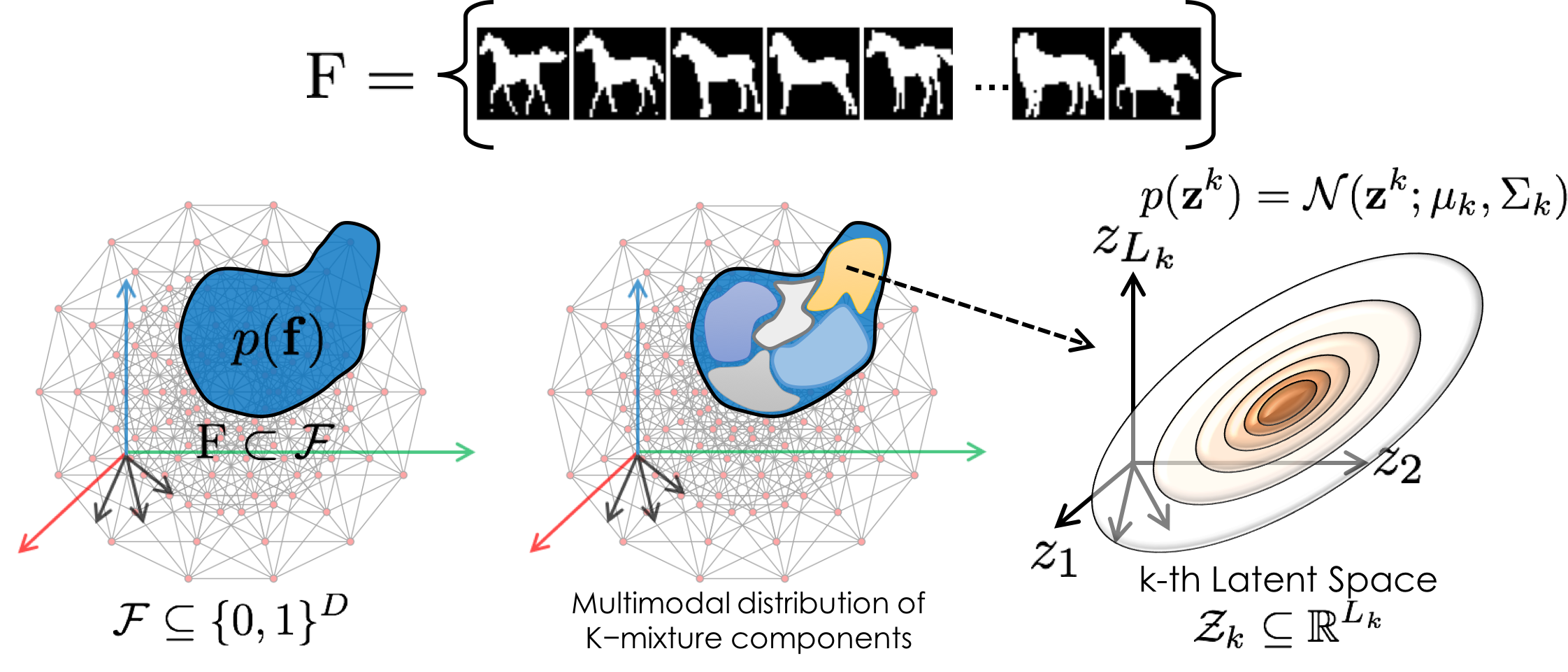
Consider an unknown shape distribution \(p(\mathbf{f})\) in the label map space \(\mathcal{F}\), of which we have only a finite ensemble. In the general case, let \(p(\mathbf{f})\) be a multimodal distribution that is comprised of \(K\)−mixture components. In our latent variable formulation, the distribution of the \(k\)−th component is governed by a low-dimensional shape-generating process of \(L_k\) independent latent variables \(\mathbf{z}_k\) where \(L_k << D\). Here we consider a class of latent Gaussian models to capture correlations between observed pixels through Gaussian latent variables.
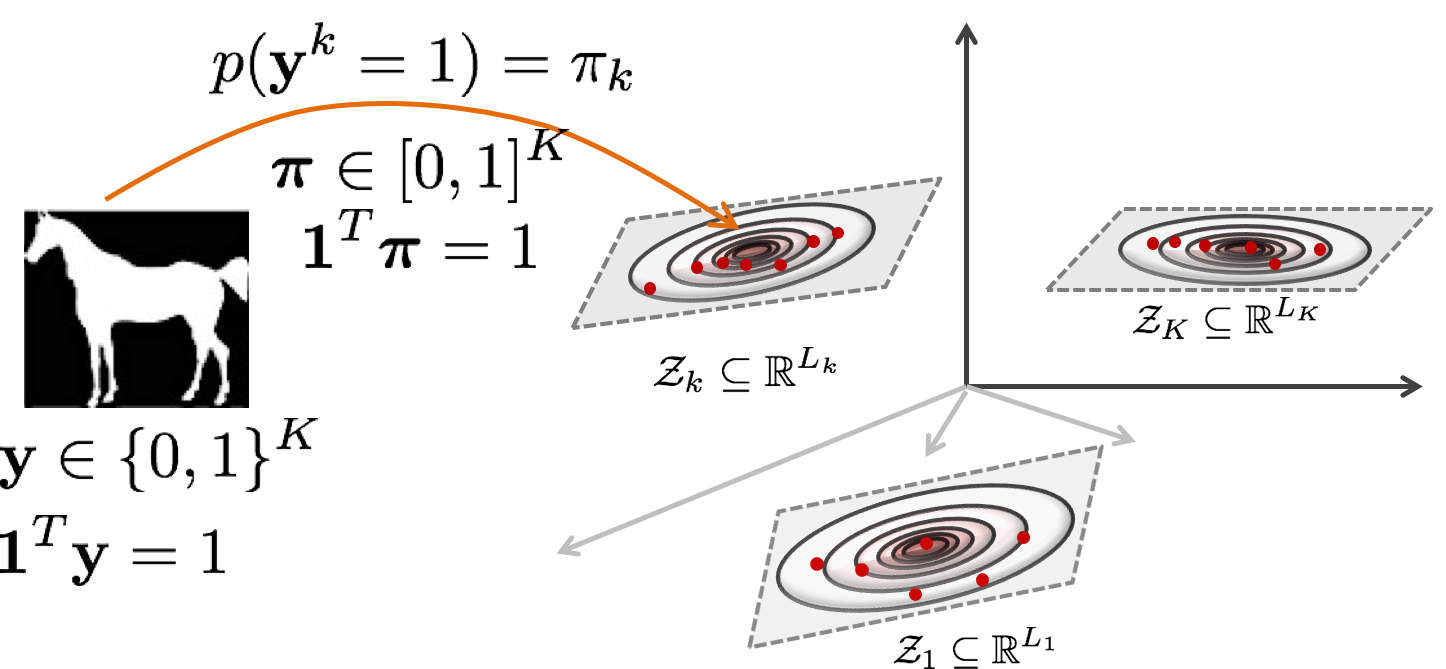
A label map is also associated with a latent binary indicator that indicates the identity of the mixture component responsible for generating it.
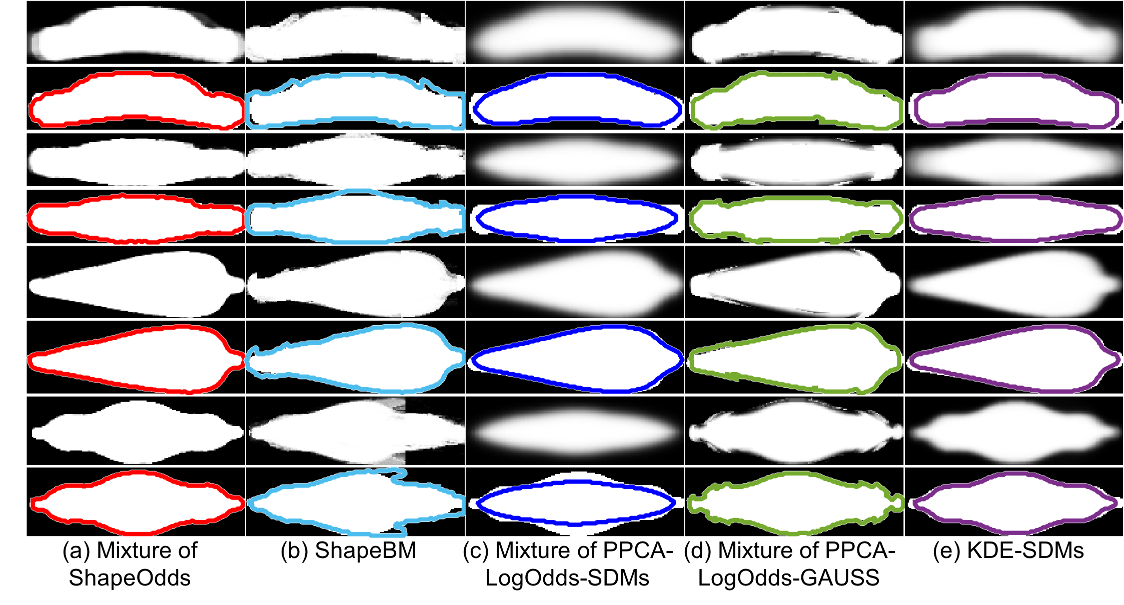
Mixture results: (odd rows) samples of estimated parameter maps and (even rows) 0.5−levelset of the parameter map overlayed on the groundtruth label map. This demonstrates that the mixture of ShapeOdds generalizes to unseen examples with crisp parameter maps compared to other baseline models. One can notice the tendency of SDMs-based models (KDE and mixture) to recover over-smoothed parameter maps, revealing a failure to learn enough shape variability and leading to parameter maps that do not preserve shape class features such as different shapes of diatom valves. The effect of ShapeBM’s space partitioning can be observed where the lack of enough receptive field overlap leads to discontinuities in the reconstructed q−map and fails to perserve global shape features.
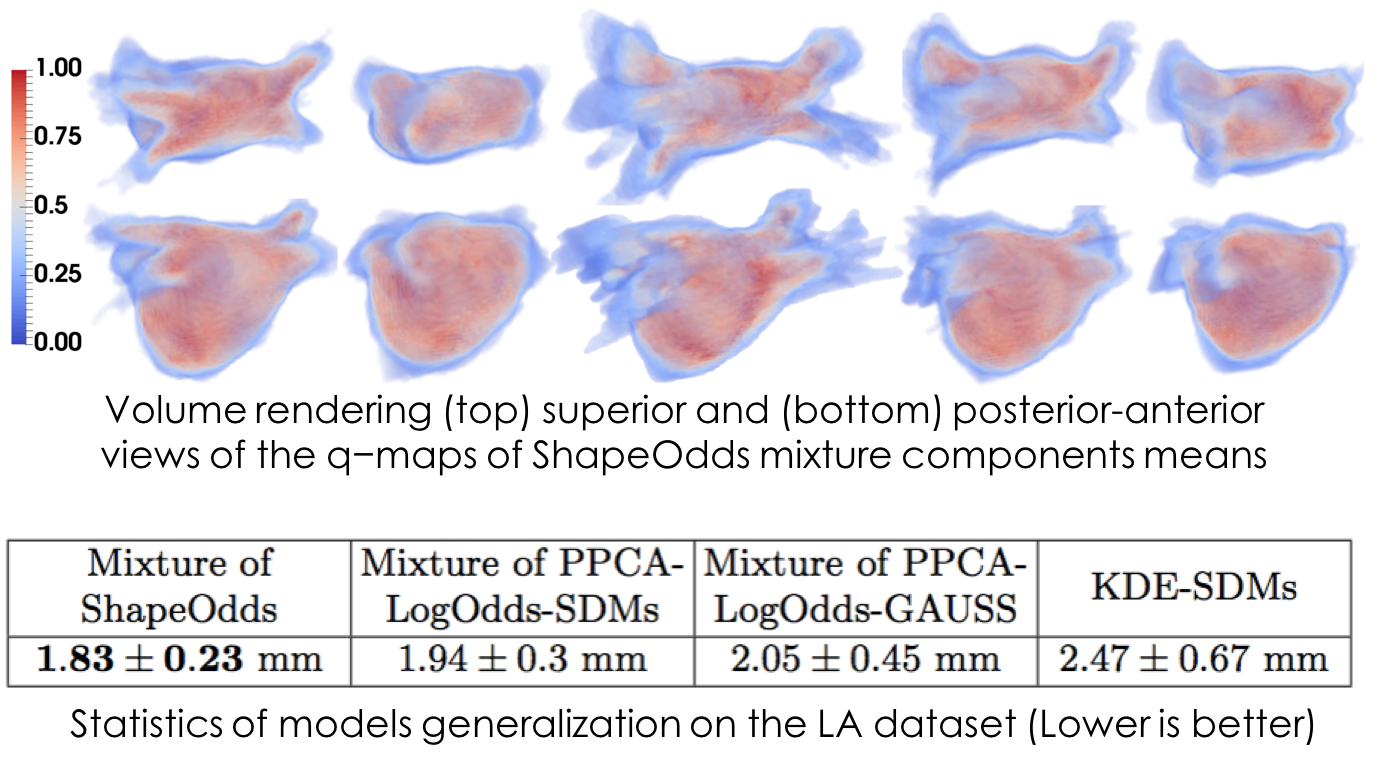
Left atrium shapes: Here we visualize the corresponding expectation parameters of the ShapeOdds mixture means. The significant left atrium shape variability is evident by having representative parameter maps that pertain to different shape characteristics, especially w.r.t. the elongation and curvature of the pulmonary veins. The table here reports the mean and std of the average boundary distance between unseen left atrium samples and estimated parameter maps from different models. The mixture of ShapeOdds is able to estimate parameter maps with 3D structure that preserve better proximity to the groundtruth shapes compared to other models.
Related publications:
Shireen Y. Elhabian and Ross T. Whitaker. From Label Maps to Generative Shape Models: A Variational Bayesian Learning Approach. In International Conference on Information Processing in Medical Imaging (IPMI), pp. 93-105, 2017.
Infinite ShapeOdds for modeling nonlinear probability distributions
Joint work with: Mike Kirby, Shandian Zhe, and Ross Whitaker
For tasks such as visualization of high-dimensional spaces and applications constrained with limited-memory mobile devices, a compact, yet meaningful parameterization that reveals an interesting structure, is crucial. Nonetheless, such a learning task is challenging due to the lack of vector space structure in the space of binary fields that leads to intractable marginals and posteriors, and nonlinear shape variations that confound methods assuming latent Gaussian models.
Recently, we extended the ShapeOdds formulation to a nonparametric Bayesian generative model, namely Infinite ShapeOdds, that is based on Gaussian processes (GPs) to derive a compact, nonlinear latent representation that efficiently captures and parametrizes the variability of binary fields, and discovers the underlying clustering structure within the latent space. Auxiliary spatial latent variables are introduced to model local interactions among pixels to learn the inherent highly nonlinear and complex spatial coherency. We further introduced a Dirichlet process prior over the latent representations to generate a meaningful compact latent space that preserves local and global structure of the data in the shape space and to simultaneously identify the number of hidden clusters and cluster memberships. Finally, for efficient model estimation, we exploited the Kronecker product properties and develop a truncated variational Expectation-Maximization algorithm. On both synthetic and real-world shape datasets, our model exhibits significant improvement over the state-of-the-art shape model of binary fields in both reconstruction and latent structure discovery.
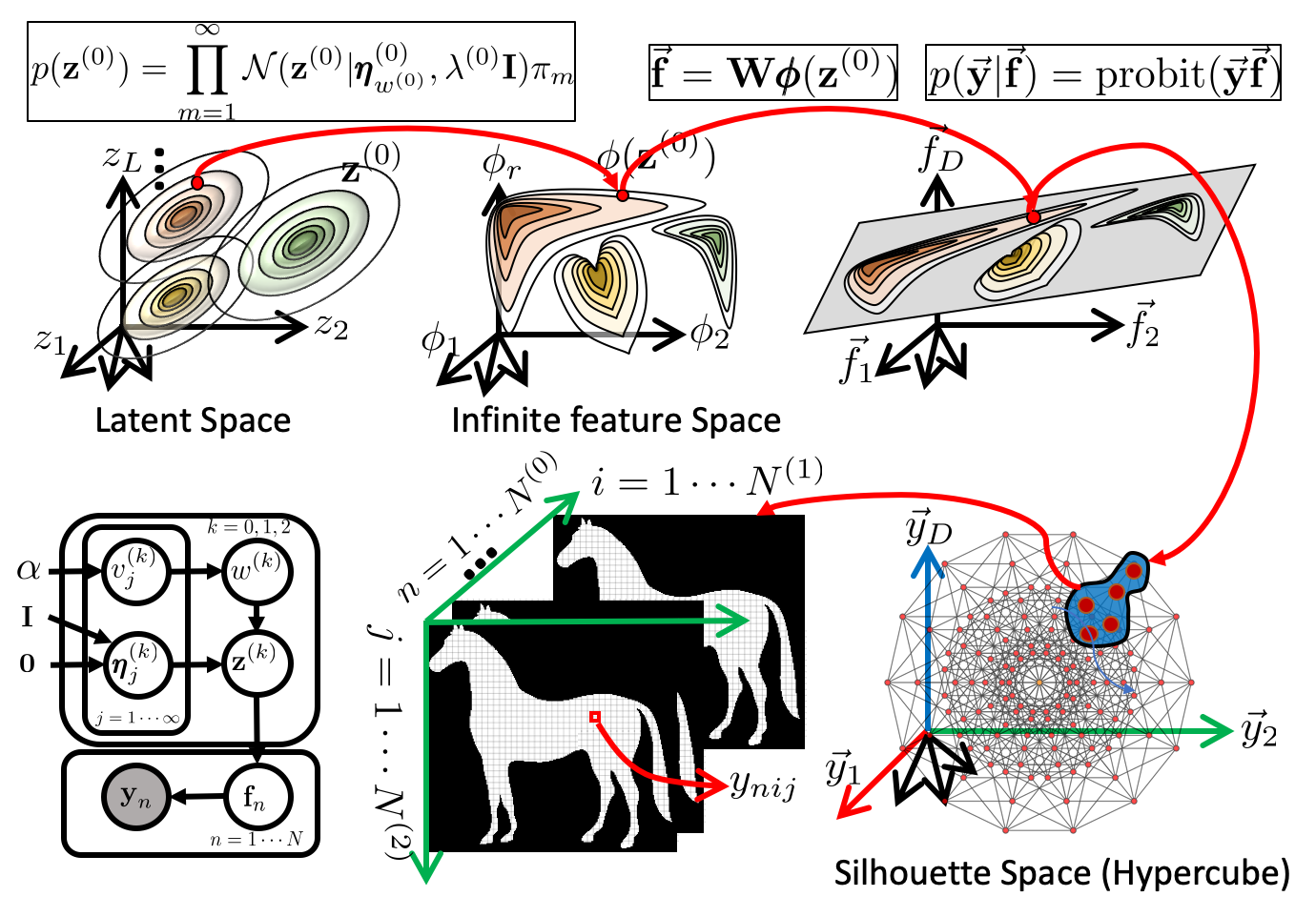
Infinite ShapeOdds: shape generating process.
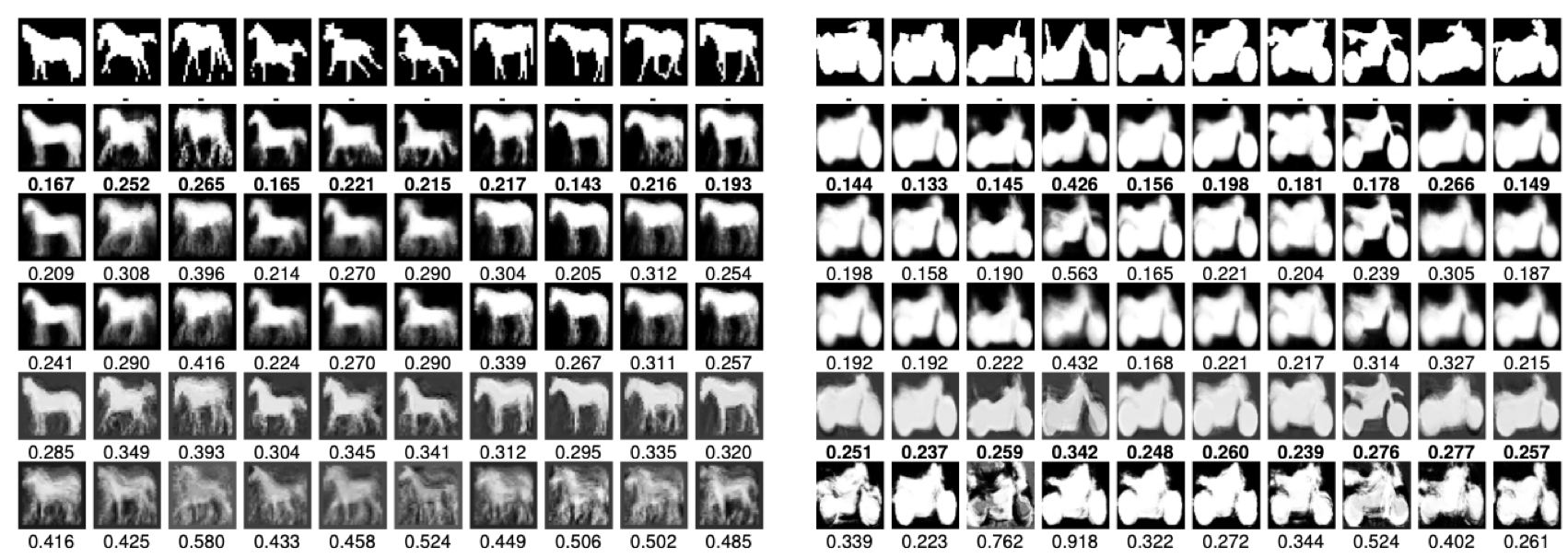
Reconstruction details for the horse and motorcycle datasets (75% training examples and 10 dimensional latent space). The rows from top to bottom: ground truth, InfShapeOdds, VAE-1, VAE-2, GPLVM, and ShapeOdds. Numbers are cross-entropies. The images reconstructed by ShapeOdds are blurred, especially in the horse dataset, implying that ShapeOdds failed to capture the nonlinear variations of the shapes using relatively lower dimensional latent space as compared to 200 dimensions in the ShapeOdds paper. In particular, results reported in the original ShapeOdds rely on unbounded latent dimensions, which are learned via the sparsity (ARD) prior. To benefit downstream applications such as visualization and structure discovery, we derive a much more compact latent space while not sacrificing the reconstruction accuracy. Hence, we limit the maximum latent dimension to be 10 and provide results for ShapeOdds with this limited latent dimensions for fair comparison.
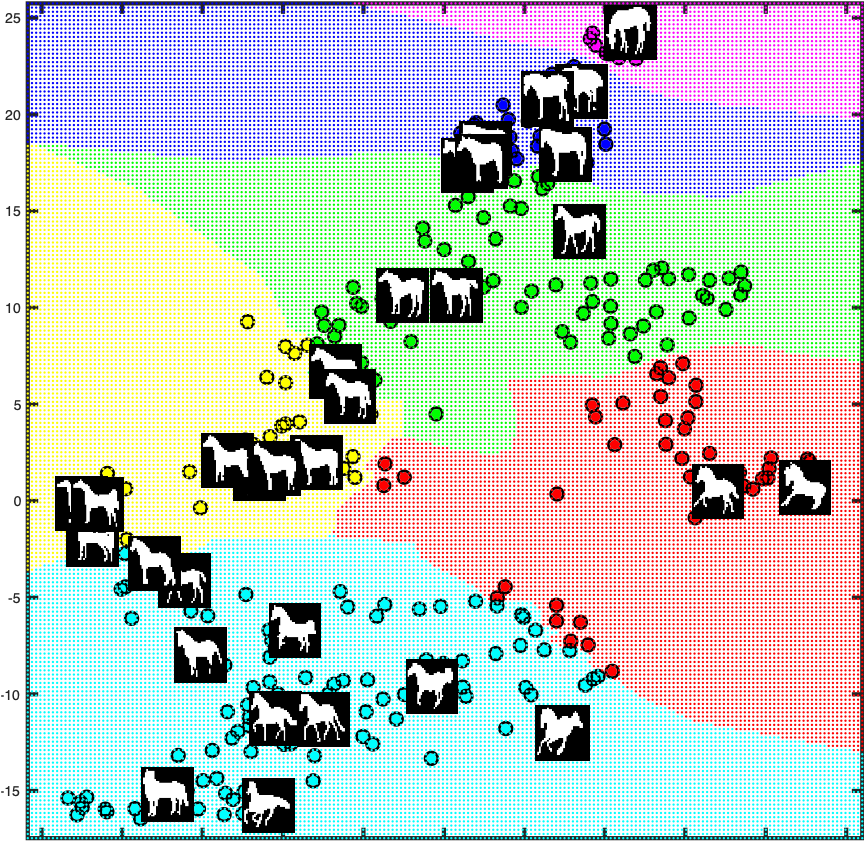
Latent clusters found by Infinite ShapeOdds on the horse dataset.
Related publications:
Wei Xing, Shireen Y. Elhabian, Ross Whitaker, Mike Kirby, Shandian Zhe. Infinite ShapeOdds: A Nonlinear Generative Model for Grid-Structured Shapes. The 34th AAAI Conference on Artificial Intelligence (AAAI), 2020.
Copyright © 2022 Shireen Y. Elhabian. All rights reserved.